

AI Agent Vol. 1【Single AgentとMulti Agent】

ChatGPTの登場以来、LLMの利用方法としては検索拡張生成[LEADGRID_SANITIZE_OPEN_PARENTHESIS]RAG[LEADGRID_SANITIZE_CLOSE_PARENTHESIS]によって内部文書の
知識を読み込ませたチャットシステムが特に注目されてきました。
しかし、近年ではこのRAGによるチャットシステムをより強固なものにするための活動が積極的に行われる一方で、次世代のAIアプリケーションとして自律的に動作するAI Agentの開発が進められています。
AI Agentとは、与えられた目標の達成のために自律的に判断および行動ができる人工知能システムのことを指します。LLMsやRAGが人間による指示に対して単発的に応答するのに対して、AI Agent では目標達成までに必要な過程を自ら推論し、複数のタスクを実行することができます。
LLMを活用したAI Agentは、LLMをコントローラとしてタスク達成のための計画を練りながら様々なツールを動作させることで人間のような意思決定能力を獲得しています。これによって、人間による追加入力を必要とせずに複雑なタスクを実行可能となることが期待されています。
例えば、以下のようなAI Agentの応用例があります。
・Skej :ユーザに代わって会議の日程調整に必要なやりとりを一括して行うAI Agent
・Jsonify: Web上のデータを調査、監視、抽出といったデータスクレイピングの一連
の流れを簡単な指示をもとに実行するAI Agent
Fig 1-A. AI Agentの応用例1: Skej
Fig 1-B. AI Agentの応用例2: Jsonify
この記事では、AI Agent のご紹介第一弾として、構築手法の最新動向をまとめたサーヴェイ論文である「 THE LANDSCAPE OF EMERGING AI AGENT ARCHITECTURES FOR REASONING, PLANNING, AND TOOL CALLING: A SURVEY 」に記載された様々な手法について紹介すると共に、AI Agent の基本的なアーキテクチャの概念である「Single Agent」と「Multi Agent」についての最新動向を紹介します。
目次
AI Agentの概要
LLMsやRAGでは、主にユーザの入力に対し自然な応答が可能であることが重視されますが、AI Agentでは具体的な目標を達成することに特に焦点を当てており、目標達成のために何が必要なのかLLM自身が計画を立てて行動をする自律的な能力を持つように設計されます。
AI Agentは推論エンジンとしてのLLMに加え、情報を補完するためのメモリストアやタスクを実行するための外部ツール等の様々な要素で構成され、これらを組み合わせて複数段階に
わたって計画やループ、リフレクションといった多様な制御構造を活用することで、目標の
達成を目指します。
堅牢な意思決定のためにはフィードバックや学習した情報に基づき計画を調整する必要が
あり、タスクのサブタスクへの分解や複数の計画の選択、外部モジュール活用、自己反省、
メモリストアの利用といった5つのアプローチに主に分類されます。
AI Agentのアーキテクチャ
AI Agent のアーキテクチャは、単一のAgent(LLM)のみで構成される「Single Agent」か、複数のAgentが協働して目標達成を目指す「Multi Agent」が存在します。
Agentはそれぞれ異なる役割(ペルソナ)を付与され、単一あるいはチームの一員として様々なメモリストアやツールにアクセスしながらタスクを実行します。
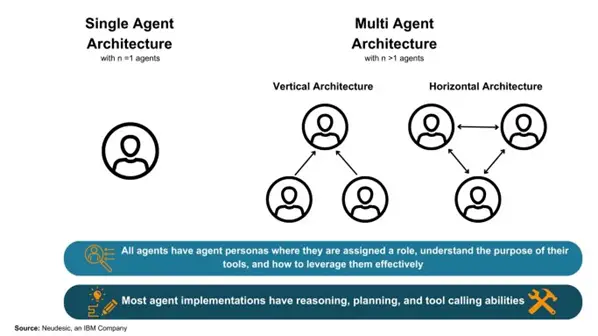
Fig 2. Single Agent とMulti Agentの構造
Single AgentとMulti Agentの違い
Single Agent は一般にツールの種類が少なくプロセスが明確に定義されたタスクに適しているとされます。Single Agentの構築には、1つのAgent(LLM)と呼び出し用のツールセットのみを必要とするため比較的容易に実装することができ、さらに Multi Agentと比べてAgent間の対話で生じるエラーやノイズを考慮する必要がありません。
一方で、推論機能や改善機能が十分でない場合、実行ループに陥り処理が進まなくなる恐れがあります。
これに対して、Multi Agent は一般に複数の視点からのフィードバックを要するタスクの
達成に適しています。
例えば、ドキュメント生成においてあるAgentがドキュメントの記述を担当し、他のAgentが生成物に対するフィードバックを提供する場合にMulti Agentアーキテクチャが利用されます。また、異なるタスクやワークフロー間で並列化が必要な場合にも用いられます。
特にZero-shot Promptingのような事前に例が提示されないシナリオにおいては、Single AgentよりもMulti Agentの方が高いパフォーマンスを示すとされます。
しかしながら、Agentに提供されるプロンプトが堅牢である場合にはMulti Agentアーキ
テクチャが必ずしも推論能力を向上するものではないと指摘されており [[2402.18272] Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?] 、
アーキテクチャの選択は必要とする推論能力ではなく、ユースケースの広さによって決定
される必要があるとされています。
Single Agent
Single Agentは、単一のLLMによって構成され、目標が達成されるまで推論/計画/ツールの実行を繰り返し行います。この構成は利用するツールの種類が少なく、プロセスが明確な
タスクに適しているとされています。
特にSingle Agentでは、適切な計画立案と計画の自己修正についての研究が進められており、以下のような様々な工夫を施した構成が提案されています。
ReAct
ReActは、タスク実行のためにどのような理由(Reasoning)でどういった行動(Acting)が必要なのかを推論する手法です。
この手法では「Reasoning→ツールの選択→実行→実行後の状況の観察」をタスク完了まで繰り返すことで目標の達成を目指します。Zero-Shot手法よりも精度が高く、思考プロセスがより明確となるため信頼性が高いとされます。

Fig 3. ReActと従来手法との動作の比較
[2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models
RAISE
RAISEは、ReActの拡張手法であり人間の短期記憶と長期記憶を導入した二重構造の記憶
システムを組み込んだ手法です。
会話選択やシーン抽出、シーン補強などの記憶を利用したAgentシナリオを含むことで、ReActに比べより複雑な複数ターンの会話におけるAgentの制御性と適応性の向上が見込めるとされています。
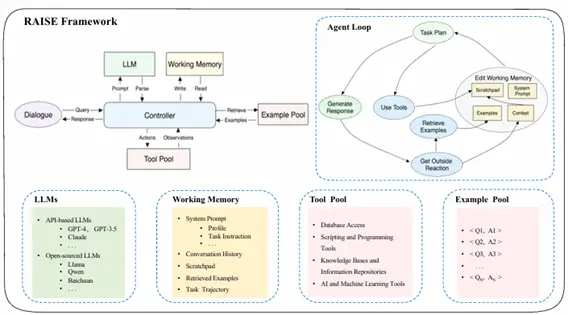
Fig 4. RAISEの概略図
[2401.02777] From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models
Reflexion
Reflexionは、Agentの実行後の状態についてLLMやその他の評価器によるフィードバックに
対して言語的に反省を行うことで、より良い意思決定へ誘導するための自己反省を取り入れる手法です。
LLMによって自己反省を行うことで言語や数値といった様々な形式のフィードバックを組み
込むことができる柔軟性を持ち、多様なタスクにおいてベースラインAgentのパフォーマンスの改善できるとされています。
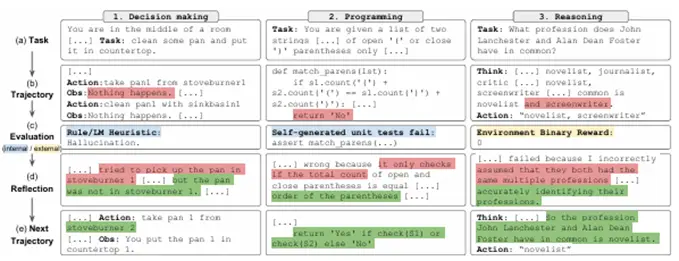
Fig 5. Reflexionの動作例
[2303.11366] Reflexion: Language Agents with Verbal Reinforcement Learning
AUTOGPT+P
AUTOGPT+Pは、ロボットに自然言語で命令を行うAgentの手法です。
この手法ではロボットのみで対応が不可能な要素について、Agentが自律的に代替案の提案やユーザの支援の要請などを行うように工夫が施されています。
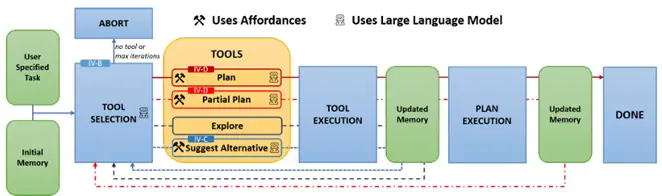
Fig 6. AutoGPT+Pのフィードバックループの概略図
[2402.10778] AutoGPT+P: Affordance-based Task Planning with Large Language Models
LATS
LATSは、他手法とは異なり木構造の探索アルゴリズムを用いて計画、行動、推論を行う
手法です。この手法ではLLM評価器と状態評価器を組み合わせた行動選択や自己反省が行われます。
多様なタスクで性能の改善が見込まれるとしていますが、他手法に比べ計算コストが大きい
欠点をもちます。
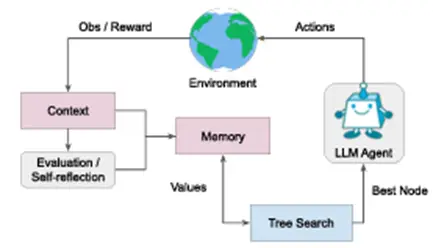
Fig 7. LATSの概略図
[2310.04406] Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Multi Agent
Multi Agentは、2つ以上の言語モデルによって構成され、各Agentが異なるペルソナを保持
しており、複数のAgentが協働しながら推論/計画/タスクの実行を繰り返し行います。
この構成では多様な役割を持つAgentが存在するため、 Single Agentに比べ特に複数の視点
からのフィードバックを必要とするタスクに適しているとされています。
Multi Agentの構成はAgent同士の関係によって以下の2つに分類されます。
Vertical:一つのリーダーAgentを中心に他のAgentを動作させる構成
Horizontal:すべてのAgentが対等に議論を行う構成
Multi Agentでは、タスク達成までの計画/実行/評価の各フェーズにおいて効果的にAgentを
編成するために、以下のような様々な工夫を施した手法が提案されています。
Embodied LLM Learn to Cooperate in Organized Teams
この研究では、Multi AgentのVertical構成におけるリーダーAgentの有効性を示されて
います。
他Agentに指示を行うリーダーAgentを導入することで、コミュニケーションに要する
コストを減らし、実行速度を向上させることができるとしています。
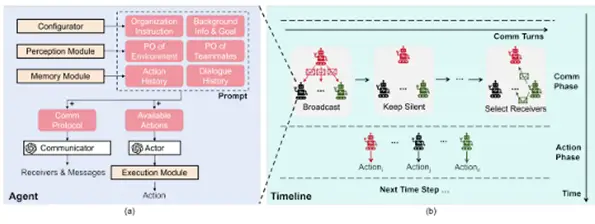
Fig 8. リーダーAgentを採用した構成の概略図
[2403.12482] Embodied LLM Agents Learn to Cooperate in Organized Teams
DyLAN
DyLANはコード生成のような複雑なタスクに特化した動的なAgent構造であり、評価器に
よってタスクに適した Agent を候補から自動で選択する手法です。
この手法ではAgentの貢献度をLLMやその他の評価器によって評価し、AgentのRerankingを
行うことでタスクに適した編成をすることができます。
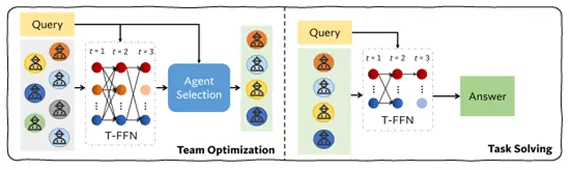
Fig 9. DyLANの概略図
[2310.02170] A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration
AgentVerse
AgentVerseでは、グループプランニングのための段階的なタスク実行の有効性が示されて
います。この研究ではタスクの実行を「再編成、意思決定、実行、評価」の4段階に分けて
行います。
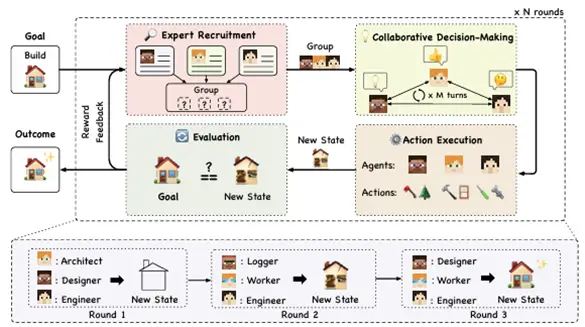
Fig 10. AgentVerseのイメージ図
[2308.10848] AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
MetaGPT
MetaGPTでは、それぞれのタスクを実行する役割をもったAgentとは別に、中間結果を
検証するAgentを活用することでエラーの低減が行われています。
またMulti AgentにおけるAgent同士の対話を構造化した出力にすることでコミュニケーションにおけるノイズを減らす工夫が施されています。
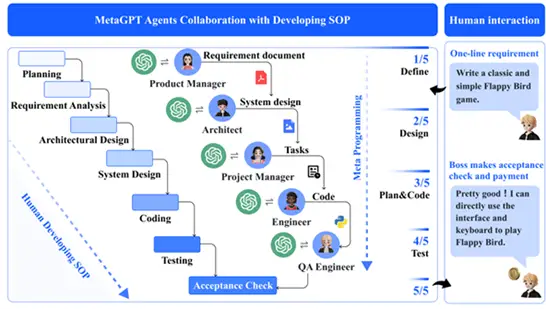
Fig 11. MetaGPTのイメージ図
[2308.00352] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
まとめ
本稿ではAI Agentについての紹介第1弾として、AI Agentの構築手法の最新動向をまとめたサーヴェイ論文である「 THE LANDSCAPE OF EMERGING AI AGENT ARCHITECTURES FOR REASONING, PLANNING, AND TOOL CALLING: A SURVEY 」を元に、AI Agentのアーキテク
チャについて「Single Agent」「Multi Agent」に分けて、それぞれで提案されている手法を紹介しました。
次回は第2弾として、本稿でもいくつか登場していたAgentが持つ4つの機能「Profiling」「Memory」「Planning」「Action」について詳しく紹介したいと思います。

記事を書いた人
釣部 勇人
理工学専攻の大学院生で、主に言語AIを扱っています。大学では、生成AIを用いた学習支援アドバイスの生成について研究しています。
関連記事

専門家向けNLP解説:vol.1 NLPとは

Behind the Product 〜 生成AIを使った製品開発の舞台裏

OpenAI Agent SDK vs. Google ADK (前編)

手書き訂正などが書き込まれた書類の、LLMを使った読み取り実験

最適化AIの進化 :LLMを使用した献立修正

AI初心者がGPT-4oで挑戦!文化庁の表記ルール、守れる?【インターン体験記 パート②】

AI初心者がGPT-4oで挑戦!日本語の誤字脱字はどこまで直せる?【インターン体験記 パート①】

Titans - Googleが描く「長期記憶型AI」 :Titans: Learning to Memorize at Test Time を斜め読み

ChatGPTのAPI利用料金比較|最新モデルo3-proも検証

OpenAI o3 & o4-mini:推論性能が向上した AIモデルの特性

LLM:量子化とファインチューニング

AI導入を成功させる!データ準備の完全ガイド

【MoA】 ローカルモデルを組み合わせてgpt-4o-miniと同等の性能?「Mixture of Agents」を試してみる

「Gemini 2.0 Flash Thinking」の画像入力を試してみる

人間のフィードバックによる強化学習とデータセット構築

OpenAI Canvas - AIと共同作業を加速する新たな作業空間 -

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Microsoft 365 Copilot:AIによる業務効率化の革新

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
