

GPT-4oを活用した画像検索システムの構築方法

調和技研 研究開発部 AI技術開発第1グループの大塚です。
OpenAIによるChatGPTの新機能として2023年9月に「GPT-4V」が発表され、画像認識機能が加わりました。これにより、画像入力に対して応答が得られるようになり、画像に対する視覚的な質問ができるようになりました。さらに、2024年5月に発表された「GPT-4o」は音声や動画にも対応したマルチモーダルなモデルであり、さらなる進化を遂げています。
当社では、このようなテキストと画像の入力から応答が得られるVision-Languageモデルを用いた技術開発に取り組んでいます。
本記事では、GPT-4oを使用して画像キャプションを含むデータベースを作成し、検索クエリ(ユーザーが入力した文章や単語)に基づいて関連する画像を見つける、画像検索システムをご紹介します。
目次
画像検索の課題
社内にある大量の画像データから目的の画像を探すのに時間がかかった経験はありませんか?
例えば「バラの花が10輪くらい、太陽光にあたっている」という画像を探したい場合、一つ一つの画像を表示しながらこれらの条件(バラ・10輪・太陽光)に合うかどうか確かめるのは非常に手間です。
そこで、検索クエリに合致する画像を取得する画像検索システムを作り、画像を探す労力を削減して効率化を図ります。
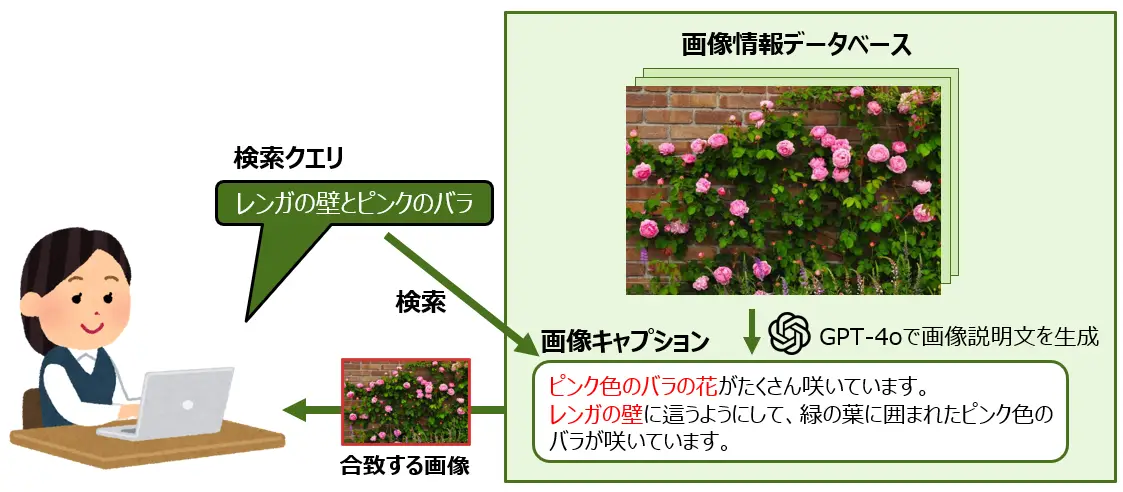
このシステムは、「花が川辺で数本揺れている」「レンガの壁とピンクのバラ」のように文章や単語(検索クエリ)を入力して検索する形式で、特定のカテゴリとして登録されていない情報や曖昧な表現・表記揺れにも対応できるようにします。これにより、事前に設定されたカテゴリから選択して検索する方法に比べて、用途が広がり便利に使えると期待されます。
また、GPT-4oに画像の説明文を生成させることで、画像から読み取れる様々な情報を文章に書き起こすことができます。この画像キャプション(画像説明文)をデータベース化し、次に説明するベクトル検索・ハイブリッド検索を行う方針で進めていきます。
ベクトル検索とは
文書検索には様々な手法がありますが、ここでは全文検索・ベクトル検索と、それらを組み合わせたハイブリッド検索について解説します。
全文検索(キーワード検索)とは、データベース内の文書の中から検索するキーワードが含まれている箇所を検索することです。例えば、「バラ」というキーワードを検索すると、データベース内の「バラ」が含まれている部分を見つけることができます。このように、キーワードと完全一致しているかどうかを検索するため、正確性に対して強みがあります。しかし、表現のゆれ(バラ・ばら・ローズ)には対応できず、検索の意図を読み取ることができないという課題があります。
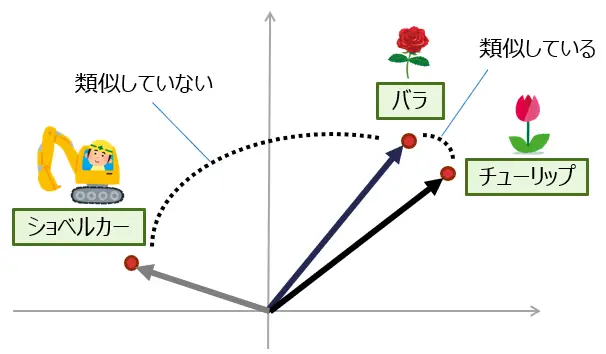
一方、ベクトル検索とはテキストを数値ベクトルとして表現し、これらのベクトル間の類似度を利用して情報を検索する手法です。このベクトルは埋め込み表現(Embeddings)と呼ばれ、意味が近いテキストの埋め込み表現同士が空間的に近いベクトルで表されるように学習して作られています。
例えば「バラ」「チューリップ」というテキストを埋め込み表現にすると[0.34, -0.23, 0.75, …]、[0.35, -0.10, 0.68, …]のように実数値の配列に変換されます。それぞれの近さは、コサイン類似度などを用いて評価され、「“バラ”, “チューリップ”」と「“バラ”, “ショベルカー”」では前者のほうが近くなり、単語の意味の近さを反映しています。このようにベクトル検索は、文章の意味を考慮した検索に対応できるところが全文検索とは異なっています。
※ 図は簡略化して2次元ベクトル空間上での埋め込み表現の位置関係を描いたイメージであり、正確なものではありません。
ハイブリッド検索は複数の検索手法の組み合わせであり、本記事では全文検索とベクトル検索を組み合わせたものをハイブリッド検索と呼ぶことにします。それぞれ検索手法の長所を組み合わせることで検索性能を向上させることができます。
画像検索システム
作成した画像検索システムの流れは下図のようになっています。
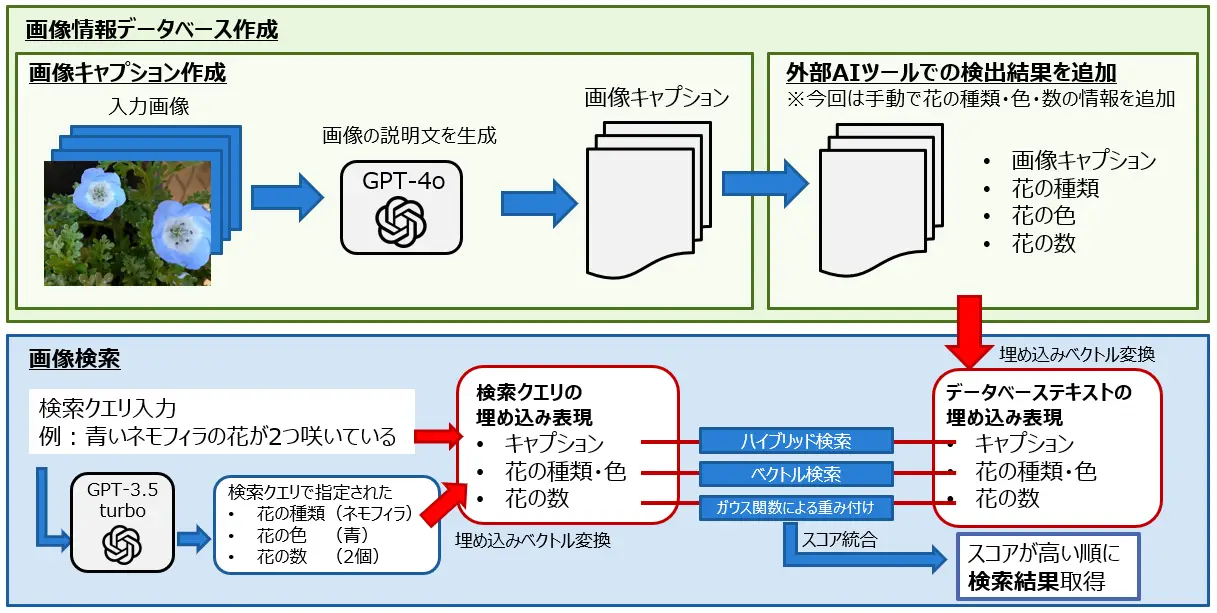
大きく分けると「画像情報データベース作成」と「画像検索」の2つから構成されています。
「画像情報データベース作成」では、手持ちの画像をGPT-4oに入力して画像の説明文を生成して、画像キャプションとしてデータベースに保存します。また、個数カウントなどの特定の目的に特化した外部AIツールがあり、GPT-4oよりも正確な検出結果が得られる場合は、この情報を合わせてデータベースに保存して検索に活用することで検索精度の向上が期待されます。
「画像検索」では、検索文の埋め込み表現と、データベース内のテキストの埋め込み表現に対してハイブリッド検索などの文書検索手法を用いて、検索クエリに近い画像を探します。
今回は花の画像検索システムを作っていきます。花の画像は「花の種類」・「花の色」・「花の個数」の情報で検索することを想定します(例:「青いネモフィラの花が2つ咲いている」)。種類や個数が様々な花画像をフリー素材サイト(ぱくたそ、写真AC)から集めて、それをもとにデータベースを作成します。
GPT-4oによる画像キャプション作成
OpenAIのAPIを用いて、GPT-4oにプロンプトで指示を与えて「花の種類」・「花の色」・「花の個数」の情報を含む画像キャプションを作ります。画像パスのリストからキャプションのリストを取得する関数は次のように書けます。
※例外処理などは省略しています。Azureのアカウントがある場合はAzure OpenAIのAPIを呼び出す方法もありますが、実装当時はAzureでGPT-4oのAPIが公開されていなかったため、OpenAIのAPIをLangChainから使用しています。(openai==1.25.0, langchain==0.1.20, langchain-openai==0.1.1)
import os
import openai
import base64
from langchain_openai import ChatOpenAI
from langchain.schema.messages import HumanMessage
# 環境変数にOpenAIのAPIキーを設定しておく
openai.api_key = os.getenv("OPENAI_API_KEY")
def caption_gpt4o(img_paths):
image_summaries = []
img_prompt = """画像に花が写っている場合、次の形式で日本語で出力してください。
(花の色)色の(花の種類)の花が(どのくらいの個数)咲いています。(画像の詳細な説明)"""
chat = ChatOpenAI(model="gpt-4o", max_tokens=1024)
for img_path in img_paths:
with open(img_path, "rb") as image_file:
img_base64 = base64.b64encode(image_file.read()).decode('utf-8')
response = chat.invoke([
HumanMessage(content=[
{"type": "text", "text": img_prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img_base64}"}}
])
])
image_summaries.append(response.content)
return image_summaries入力画像と生成された画像の説明文(画像キャプション)の例を示すと、次のとおりです。

花の数については、数が多くなるにつれて多少の間違いはあるものの、実際の個数に近い数を含む文章が生成されています。10輪以上になると「複数」「たくさん」などの語彙で出力されることが多いようです。背景情報についても読み取って文章化されています。
データベース情報追加
画像キャプションを次のようにJSON形式で保存します。上で示した通り、GPT-4oの画像認識は、全体の雰囲気の説明は得意な傾向がありますが、花の個数カウントなど正確性を要求されるタスクに対しては誤った回答を返すことがあります。そこで、物体検出などのタスクに特化した他のAIツールと併用して正確なデータを追加することで検索精度を上げたいと思います。
今回は“flowers”, “colors”, “quantity”の3つの項目を作成して、それらの項目の情報は手作業で追加しました。
"input_path": "input/flower_count/nemophila_1.jpg", "flowers": ["ネモフィラ"], "colors": ["青"], "quantity":2, "summary": "青色のネモフィラの花が2つ咲いています。緑の葉に囲まれた青いネモフィラの花が二つ並んで咲いています。背景にはレンガのような模様が見えます。"} |
これで花の画像情報データベースができました。
画像検索
次に検索システムを作ります。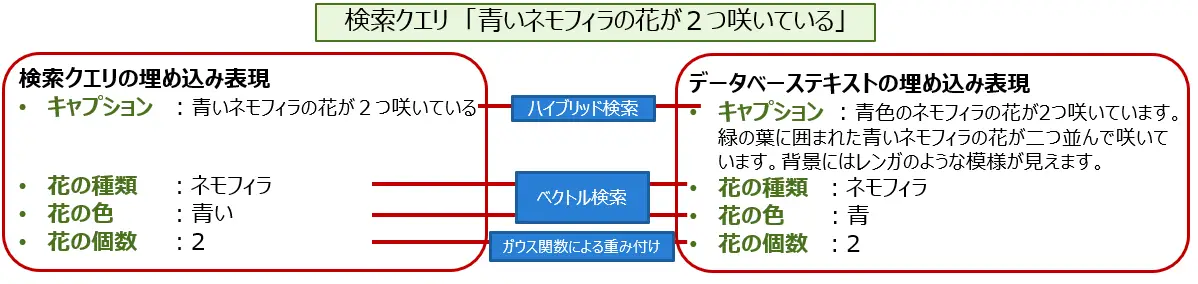
まずは検索クエリで指定された「花の種類」・「花の色」・「花の個数」の情報をGPT(API経由でgpt-3.5turboを使用)に聞いて取り出します(例:検索クエリ「青いネモフィラの花が2つ咲いている」 → 「花の種類:ネモフィラ」、「花の色:青い」、「花の個数:2」)。
次に、埋め込み表現に変換した後、これらの項目ごとにデータベースに保存されている項目と比較します。文字列の比較の場合、検索クエリとデータベースのテキストを埋め込み表現にして、ベクトル検索(コサイン類似度)のスコアを算出します。例えば「花の色」の比較では、検索クエリに「青い」と入力された場合、データベースが「青」となっていれば高いスコアを出し、「赤」となっていれば低いスコアを出します。
花の個数は数値であるため、ガウス関数を用いて、値が近いほど大きいスコアを出力するようにしました。検索クエリで指定されなかった項目についてはスキップされます。
また、保存されている項目以外の検索情報(例:「太陽光にあたっている」)を反映させるために、検索クエリそのものとデータベースの画像キャプションに対してハイブリッド検索を行ってスコアを取得します。
最後にこれらのスコアを統合して最終的なスコアを決定します。
文書検索の実装は、OpenAIのEmbeddings APIを使うと簡単にできます。埋め込み表現への変換は”text-embedding-ada-002”というEmbeddingモデルを使用しました。また、ハイブリッド検索に含まれる全文検索のアルゴリズムには、BM25を用いました。
ベクトル検索におけるコサイン類似度の取得について、Azure OpenAIを利用した実装例は次のとおりです。
import os
from openai import AzureOpenAI
from scipy.spatial.distance import cosine
model = AzureOpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2023-05-15",
azure_endpoint =os.getenv("AZURE_OPENAI_ENDPOINT")
)
def get_embedding(prompt):
vec = model.embeddings.create(
input = prompt,
model= "text-embedding-ada-002"
).data[0].embedding
return vec
search_query = "検索クエリ" # 例:「バラ」
database_text = "データベースから抽出したテキスト" # 例:「マーガレット」
# 埋め込み表現に変換
query_embedding = get_embedding(search_query)
database_text_embedding = get_embedding(database_text)
# コサイン類似度
score = 1-cosine(query_embedding, database_text_embedding)実際に使ってみる/花の画像検索
GradioというPythonライブラリを使って、上で作成したシステムをWebブラウザ上で実行できるようにしてみました。以下の画像が実際の実行画面です。
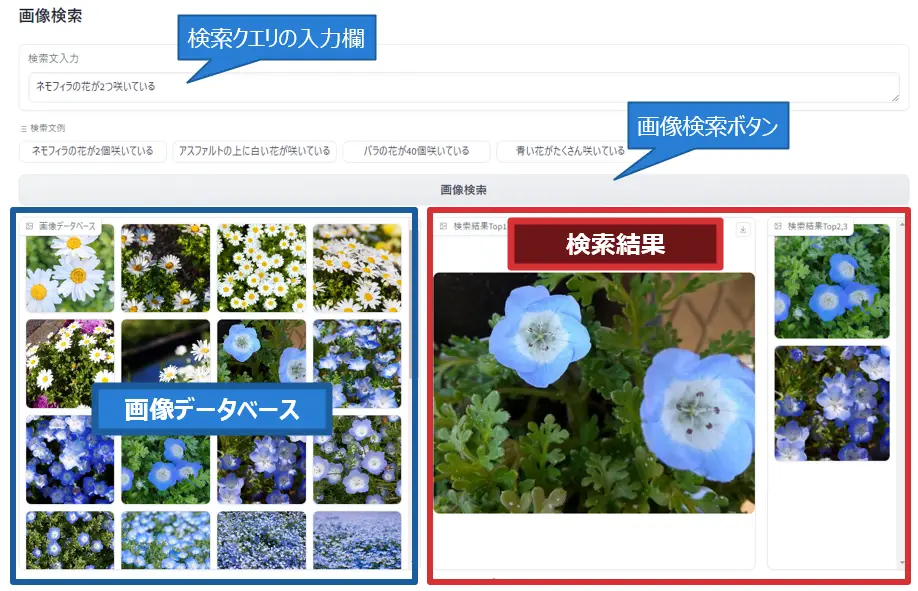
上部のテキストボックスが検索クエリの入力欄で、ここにユーザーが検索したい画像を表す文章を入力します。左下にはデータベース内の画像一覧が小さいサイズで表示されています。「画像検索」ボタンを押すと、先述した画像検索のコードが実行されて右下に検索結果の画像が表示されます。検索結果の中で大きく表示されている画像が、最もスコアの高い画像です。
上の画面には「ネモフィラの花が2つ咲いている」という検索クエリを入力した場合の結果が表示されています。最も大きく表示されている画像はネモフィラの花が2つ咲いている画像なので正しい結果といえます。スコアが2, 3番目の画像も、近い数のネモフィラの花が表示されています。以下に検索結果のみを切り抜いた画像を載せています。
つぎに、「アスファルトの上に白い花が咲いている」と入力して検索してみます。
すると、指定通りアスファルトが少し見えている画像が表示されました。このように、背景の情報も含めた検索ができることが確認できました。
今後の展望
データベース作成の際に、花の種類や個数を手入力しましたが、物体検出に特化したYOLOなどのAIツールと組み合わせて自動化できると、データベース作成がさらに効率よくできると思います。
また、動画から特徴的なフレームを切り出す仕組みを導入すれば、動画検索に応用可能です。大量の動画データから特徴的な動作やシーンを自動的に抽出することもできるようになると考えられます。
さまざまな画像や動画への応用も
本記事では、GPT-4oを用いた画像検索システムの作り方について紹介しました。
はじめに、手持ちの画像に対してGPT-4oを用いて画像キャプションを含む画像情報データベースを作成しました。次に、花の種類などの新しい項目を追加してデータベースに情報を入力しました。物体検出などの他のAIツールを用いて得た精度の高い結果を追加することで検索精度が向上すると期待されますが、今回は手作業で入力しました。最後に、作成した画像情報データベースに対して、ベクトル検索・ハイブリッド検索を用いて検索クエリに近い画像を得られるようにしました。
今回は花の画像検索を紹介しましたが、他の画像や動画に焦点を当てた検索をできるようにしたい場合は、それに特化したカスタマイズも検討可能です。既存の画像検索に関する課題をお持ちでしたら、ぜひ調和技研にご相談ください!

記事を書いた人
大塚 茜
早稲田大学先進理工学部物理学科で助手を務めた後、IT企業に就職し、エンジニアとして画像処理・AIを中心とした案件のソフトウェア研究開発や技術調査を経験。子供2人を育てながらリモートワークで柔軟に働ける環境を探して、2023年4月に調和技研に入社。画像処理技術や大規模言語モデル(LLM)を活用したAIプロダクト開発に従事。AI技術をより身近なものとして、次世代に伝えていきたいです。
関連記事

OpenAI Canvas - AIと共同作業を加速する新たな作業空間 -

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
