

3次元点群データとAIを用いたオガ粉の体積計測

調和技研 研究開発部に所属しているMd Shafiqul Islamです。調和技研には北海道ならではの課題も含め、様々なご相談が寄せられます。今回は「点群データとAIで農業関連商品の数量計測ができないか」という研究をもとに記事を書きました。同じような課題を持つ企業の皆さまのご参考になれば幸いです。
点群データは複雑な3次元形状を表現するのに適していることから、様々な分野や用途で利用されています。点群データから体積を計測することは、土木工学、鉱業、農業、環境科学など、さまざまな分野で必要な作業です。このプロセスでは、点群から3Dモデルを作成し、そのモデルで表現される物体の体積が計算されます。本記事では、3次元点群データからオガ粉の体積を計算する詳細な手順をステップごとに説明していきます。
(※本記事はMd Shafiqul Islamが執筆したオリジナルの英語記事を日本語に訳したものです)
目次
背景と目的
土砂や農作物、資材などが積み上げられた山の体積を計測するのは手間がかかります。そこでAIを活用し、人手不足に悩む企業に簡単に導入できるサービスを提供できれば非常に助かると考え、今回はオガ粉を対象に開発に取り組みました。
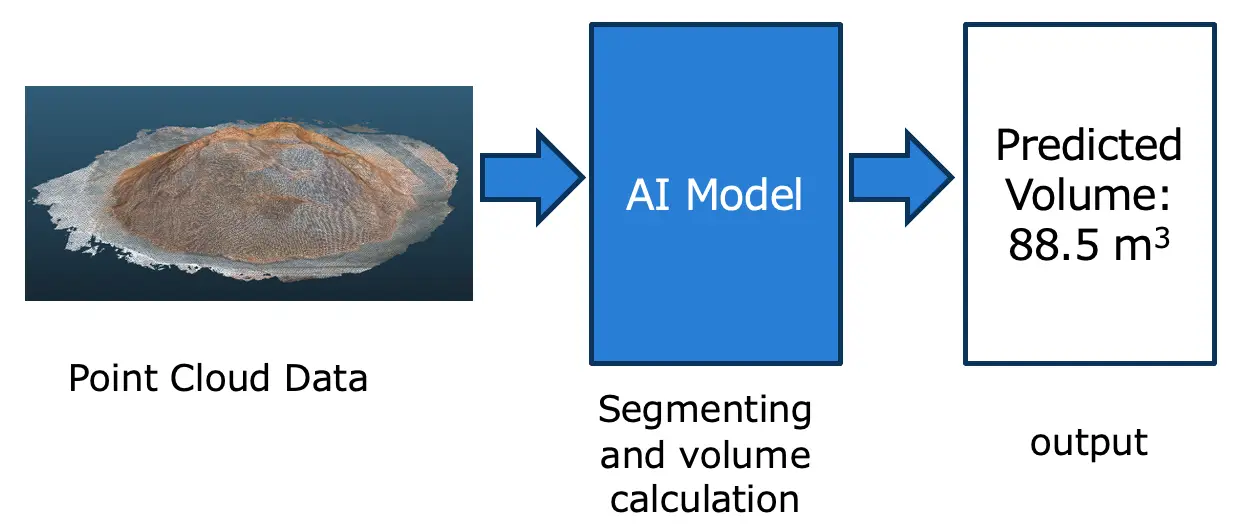 図1:体積計算図1は、体積計算の概要を示したものです。AIモデルはオガ粉データ(点群データ)を入力とし、体積を出力します。
図1:体積計算図1は、体積計算の概要を示したものです。AIモデルはオガ粉データ(点群データ)を入力とし、体積を出力します。
点群とは
点群とは、3次元空間に配置された多数の離散点からなるデータで、3Dモデルの基本的な表現方法の一種です。点群の各点は、X、Y、Z軸上の座標によって定義されます。多くの場合、これらの点はRGBフォーマットで記録された色や、各点の明るさを示す輝度値などの追加情報も持っています。
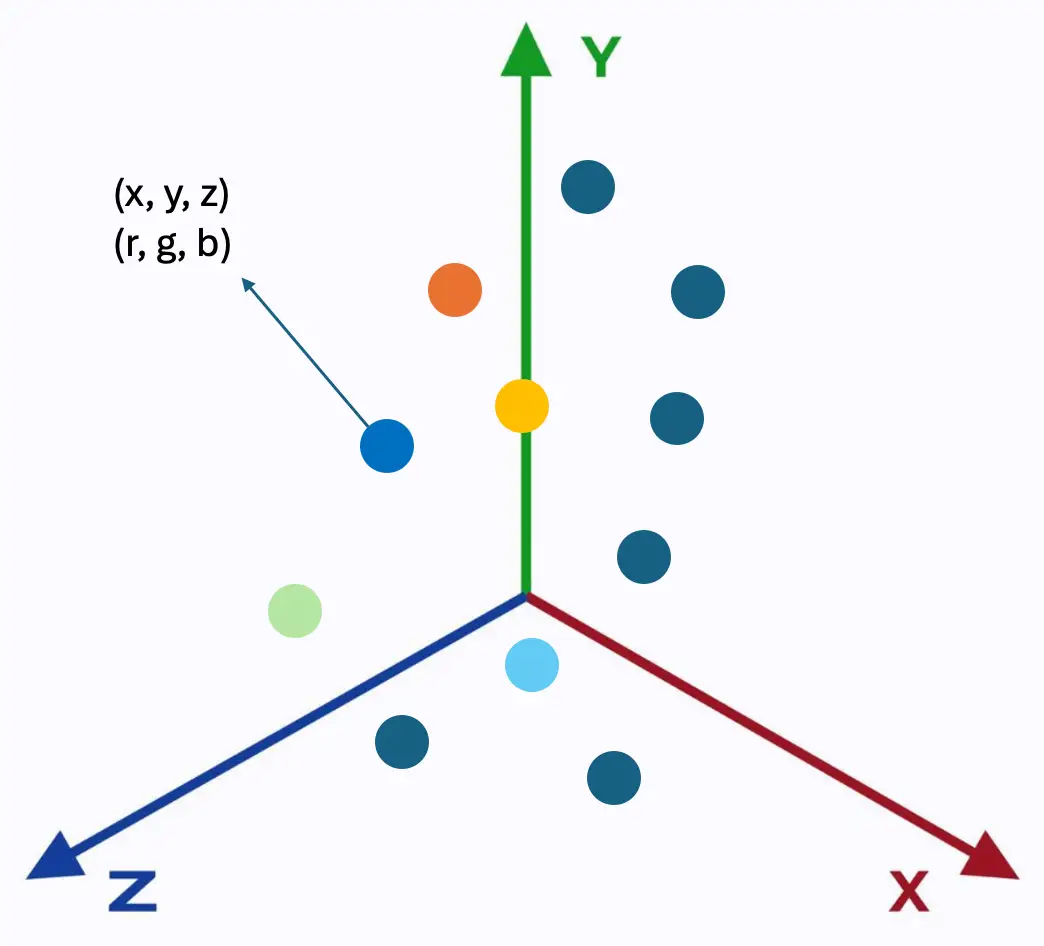 図2:点群
図2:点群
図2では、点は3次元座標上に表現されており、x,y,z座標と色の値を保持しています。点群データを保存する最も一般的なファイル形式はLASフォーマットで、このバイナリファイル形式は、LiDAR特有の情報を損なうことなく保持できます。
点群は、対象物や構造物をスキャンすることで作成されます。スキャンは、レーザースキャナーを使用するか、フォトグラメトリと呼ばれる手法で行います。
レーザースキャナ
レーザースキャナ、特にLight Detection and Ranging(LiDAR)技術を使用するものは、物体の表面に多数の光パルスを照射し、各パルスが跳ね返ってくるまでの時間を測定する方法をとります。各パルスは、対象物上の点の正確な位置を特定し、それぞれの点が全体として点群を形成します。これらの測定値は収集・処理されて点群データとしてまとめられ、対象の物体のデジタル表現となります。
フォトグラメトリ
写真から3次元データを作成する方法です。異なる角度から複数の写真を重ね合わせて撮影し、ソフトウェアを使ってこれらの画像を解析して共通点を検出し、対象物の形状と位置を3次元的に再構築します。プロセスとしては、画像を取り込み、画像を処理して写真測量モデルを作成し、モデルを改良して精度とディテールを向上させる、という複数の段階に分かれます。
データ分析
AIモデルを学習させるためには、データを準備する必要があります。続いては、データの取得プロセス、ファイルから意味のある情報を抽出する方法、点群データを可視化する方法について説明していきます。
データ収集
今回は複数のオガ粉の山について、LiDARスキャナを搭載したiPhone 12 Proで、図3のScaniverseというアプリを使用してデータを収集し、LASファイルとして保存しました。このアプリでは、データから目的の部分を切り抜くこともできます。
 図3:Scaniverseアプリ
図3:Scaniverseアプリ
データ抽出
3次元点群データはLASファイル(.las)で保存されます。LASファイルから必要なデータを抽出するには、laspy(Pythonのライブラリ)を使用します。LASファイルのデータは、各点のx,y,z座標、各点のRGBカラー値、各点の分類値など、いくつかのプロパティを持っています。各点の分類値は非常に重要です。点をグループにセグメンテーションするAIモデルを作りたい場合は、アノテーションにおいて各点にクラスラベルを割り当てて教師データとします。
データの可視化
各点群ファイルには多くの点(~300,000点)が含まれています。点群を可視化するために、CloudCompareやPointlyなど多くのツールがあります。
 図4:オガ粉点群データの可視化
図4:オガ粉点群データの可視化
図4はCloudCompareを使用して、オガ粉の3次元点群データを可視化したものです。
アノテーション
どのようなモデルのトレーニングにおいても、アノテーションは非常に重要です。我々のモデルを学習させるためには、3次元点群データにアノテーションを付ける必要があります。対象となるデータには、オガ粉、床、その他のオブジェクト(壁や車など)が含まれます。今回はオガ粉部分(ターゲット)にはラベル「0」を、ターゲット以外の部分(床、車、壁など)にはラベル「1」を割り当てました。
アノテーションツール
3次元点群データのアノテーションツールは数多く存在しており、例えば、CloudCompare(無料)、Pointly、LabelCloud、VRMESH、CVATなどがあります。今回はCloudCompareをアノテーションに使用しました。
アノテーションのプロセス
CloudCompareを使って点群データのアノテーションを行うには、いくつかのステップが必要です。ここでは、オガ粉データに対してアノテーションする手順について順を追って説明します。
1. CloudCompareで点群データをインポートする
2. ターゲット領域を囲むセグメント線を引く
3. ターゲット領域にラベルを割り当てる(図5)
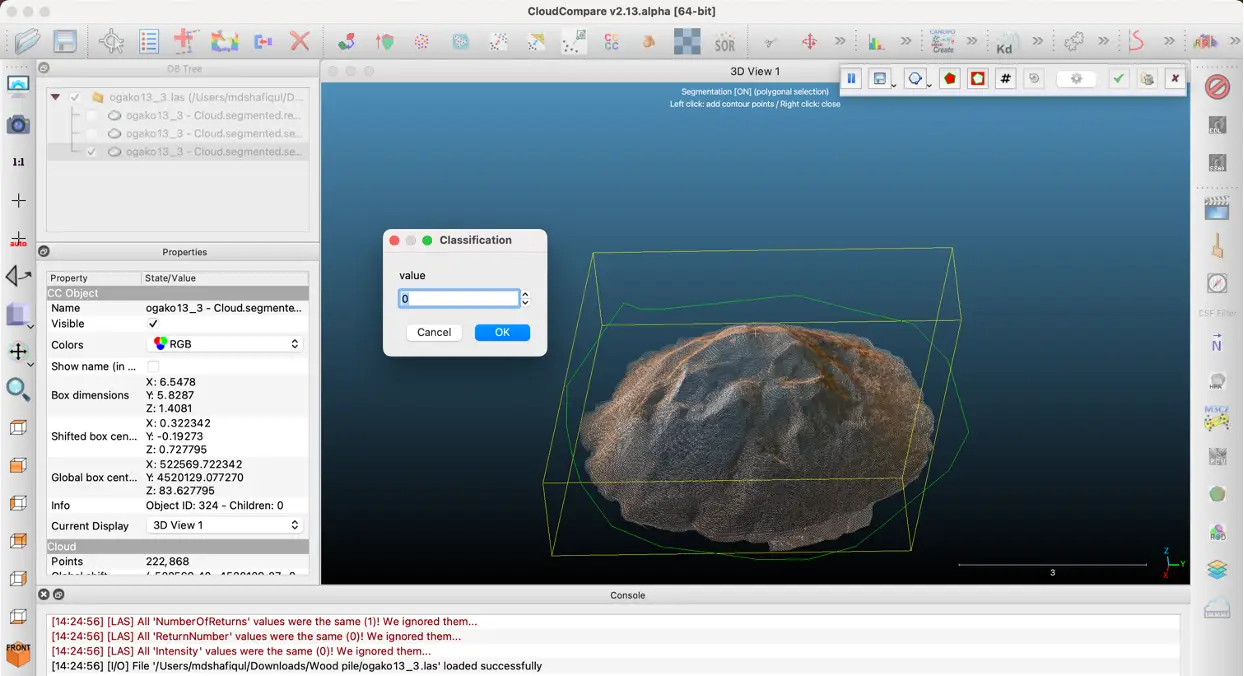 図5:ラベリングされた切り取り領域
図5:ラベリングされた切り取り領域
4. 分割した領域を切り抜き、保存する
5. すべてのセグメント化された領域を選択する(図6)
6. 「Merge Multiple Cloud」ボタン(赤い丸の箇所)をクリックし、マージされた1つのファイルを作成する
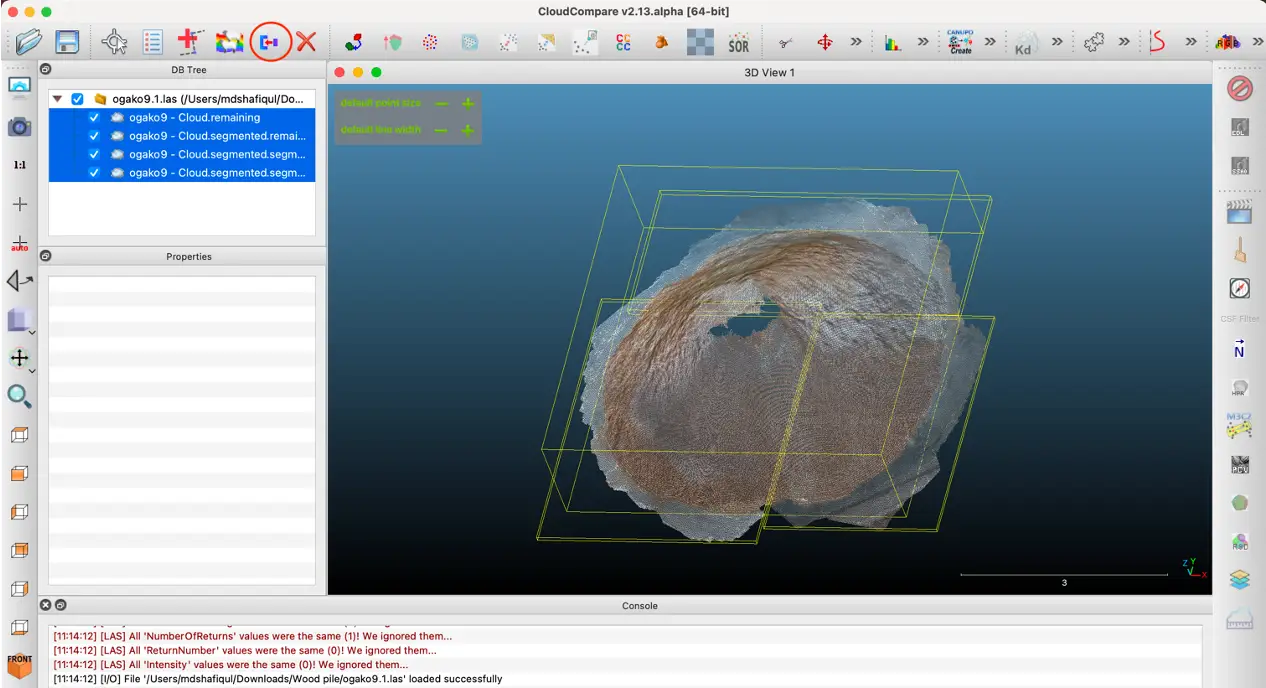 図6:セグメント化された領域のマージ
図6:セグメント化された領域のマージ
7. "Classification "の値に基づいて、各セグメントを異なる色で表示する(図7、8)。
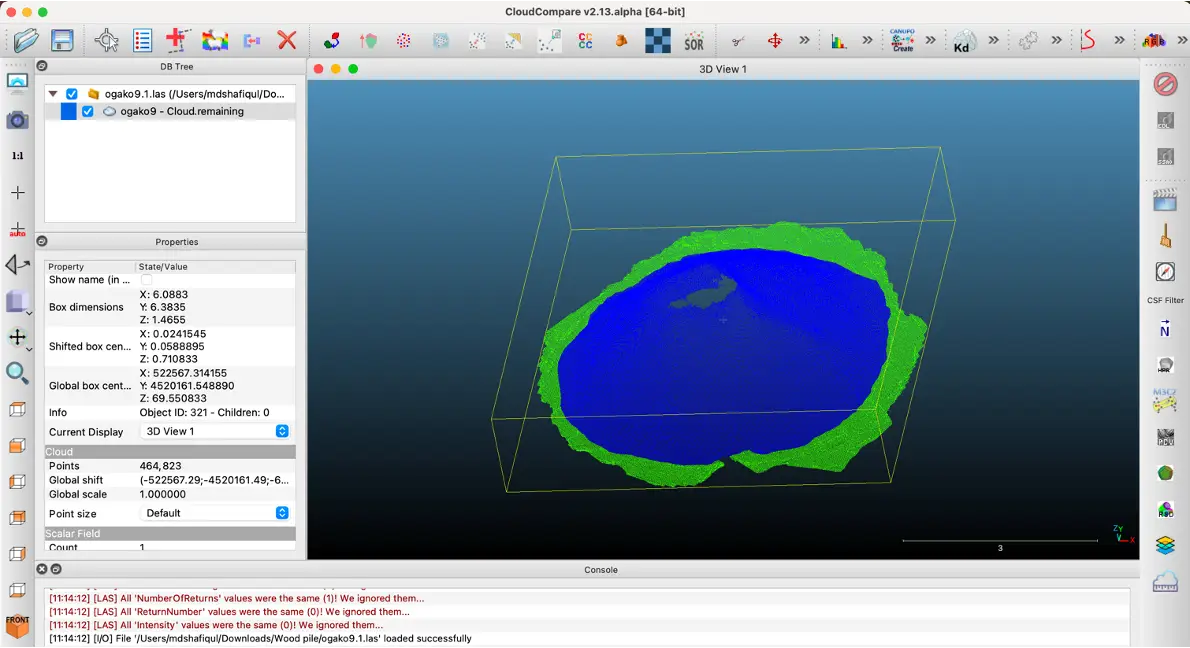 図7:アノテーションの出力
図7:アノテーションの出力
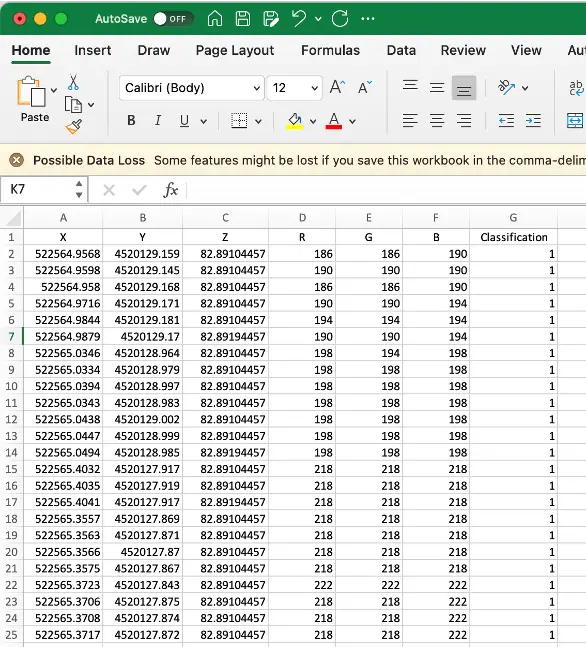 図8:アノテーションの出力
図8:アノテーションの出力
8. アノテーション後の点群データを任意のフォーマットで保存する(.las / .csv など)
PointNetモデル
オガ粉の体積を計算するためには、3Dセマンティック・セグメンテーションを行う必要があります。点群データを扱うモデルはPointNet、RangeNet、2DPassなど数多くあります。点群データと入力画像の両方を必要とするモデルもあれば、点群データだけで動作するモデルもあります。
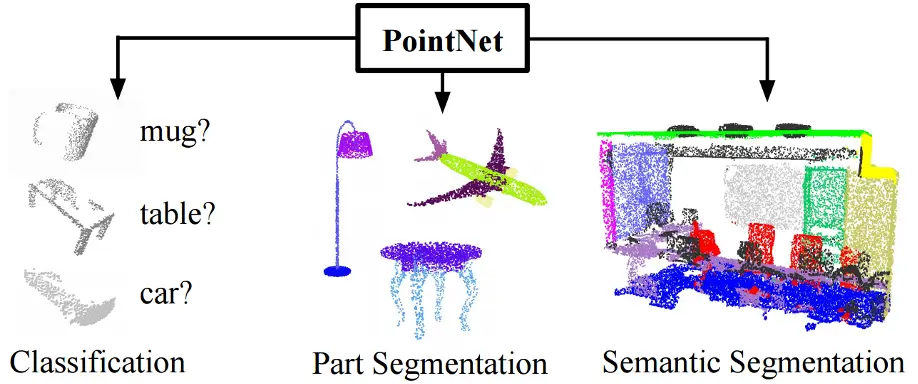 図9:PointNet(論文より)
図9:PointNet(論文より)
PointNetは点群データのみで動作する新しいアーキテクチャで、入力の外部画像を必要としません。図9は、PointNetモデルの様々な分野での応用可能性を示しています(分類セグメンテーションなど)。今回はこのPointNetをオガ粉の体積計測に使用しました。
PointNetはポイントベースのアーキテクチャであり、構造化されていない点群の入力に対応しています。ここでPointNetモデル・アーキテクチャの概要を説明しておきます。
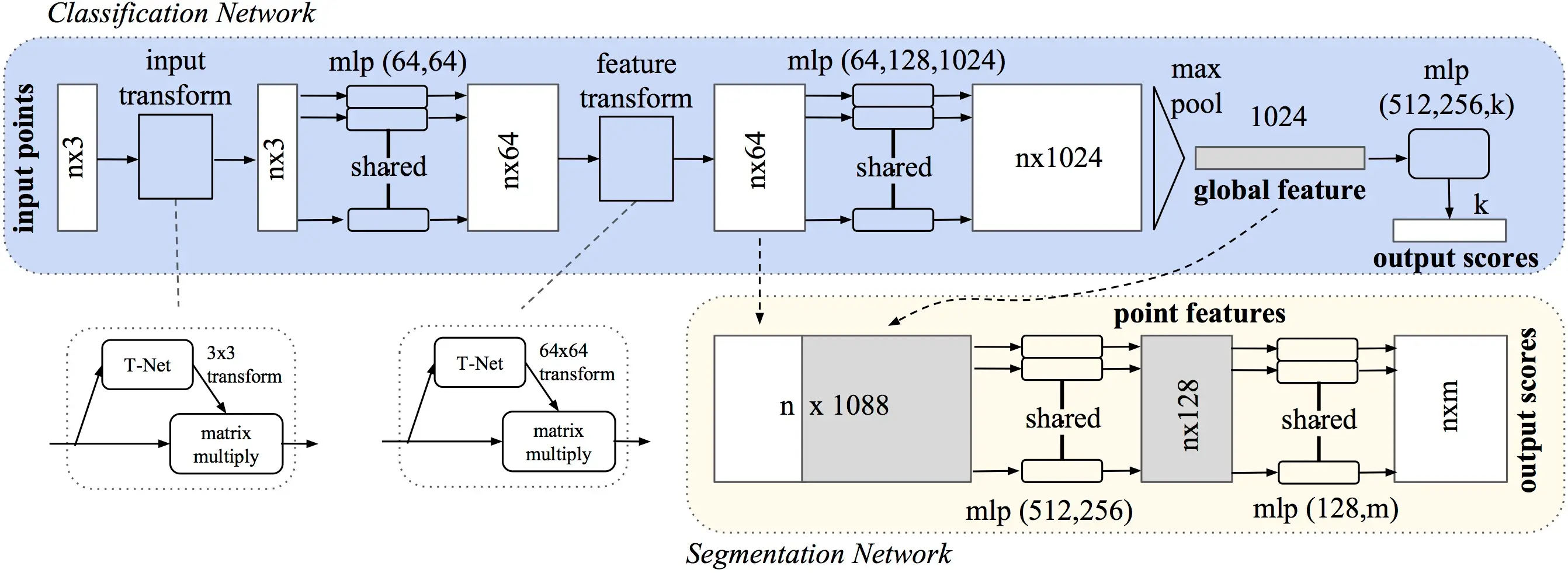 図10:PointNetのアーキテクチャ(PointNetの論文より)
図10:PointNetのアーキテクチャ(PointNetの論文より)
図10はPointNetモデルの全体的なアーキテクチャを表したものです。分類ネットワークはn個の点を入力とし、入力変換と特徴変換を行い、最大プーリングによって点の特徴を集約します。出力は m 個のクラスに対する分類スコアです。セグメンテーションネットワークは、分類ネットワークを拡張したものです。 mlp は多層パーセプトロンを表し、括弧内の数字は層のサイズを示します。
PointNetは視点を変えて学習する必要はありません。視点に関係なく点群を認識するように学習できます。PointNetではT-Netと呼ばれるサブモジュールを使ってこれを行います。
分類ネットワークは、グローバル特徴量(分類用)またはローカル特徴量とグローバル特徴量の連結(セグメンテーションネットワークへの入力用)を返します。
セグメンテーションネットワークは、学習されたローカル特徴量とグローバル特徴量の連結を入力とします。グローバル特徴量はn個のローカル特徴量それぞれと連結されます。アーキテクチャは一連の共有MLPで構成され、最終層は各ポイントをm個の可能なクラスに分類します。アーキテクチャの詳細は原著論文を参照してください。
体積計測パイプライン
点群データから体積を計測するには、いくつかのステップを踏む必要があります。具体的には、データの前処理、セグメンテーション、異常値除去、座標シフト、三角メッシュ生成、メッシュからの体積計算、というプロセスがあります
 図11:パイプライン
図11:パイプライン
図11にボリューム計測パイプラインの全ステップを示します。データの前処理ステップでは、各点群ファイルから複数のサンプルを抽出します。次に、点群データを複数のセグメントに分割するAIモデルの学習を行います。セグメンテーションでは、データをターゲット(オガ粉)と非ターゲット(床、壁)の2つに分割します。セグメンテーションの後、異常値を除去する後処理が行われます。次に、点群全体の中心座標が(0, 0)ベースになるように、点群のX座標とY座標をシフトします。座標シフト後、セグメント化された点群データから三角メッシュが生成されます。最後に、各三角形メッシュの体積を計算し、合計して木材パイル全体の体積を求めます。体積計測パイプラインのいくつかのステップを以下に簡単に説明していきます。
セグメンテーション
オガ粉の体積を計測するためには、ターゲットとなるオガ粉の点と非ターゲットの点(床や壁など)を分離する必要があります。分離するには、セマンティックセグメンテーションを行います。このステップでは、そのために、アノテーションした点群データを用いてPointNetモデルを学習させます。モデルは点群サンプリングデータを入力とし、それらをターゲットクラスにセグメンテーションします。これは各ポイントにクラスラベルを割り当てることを意味します。
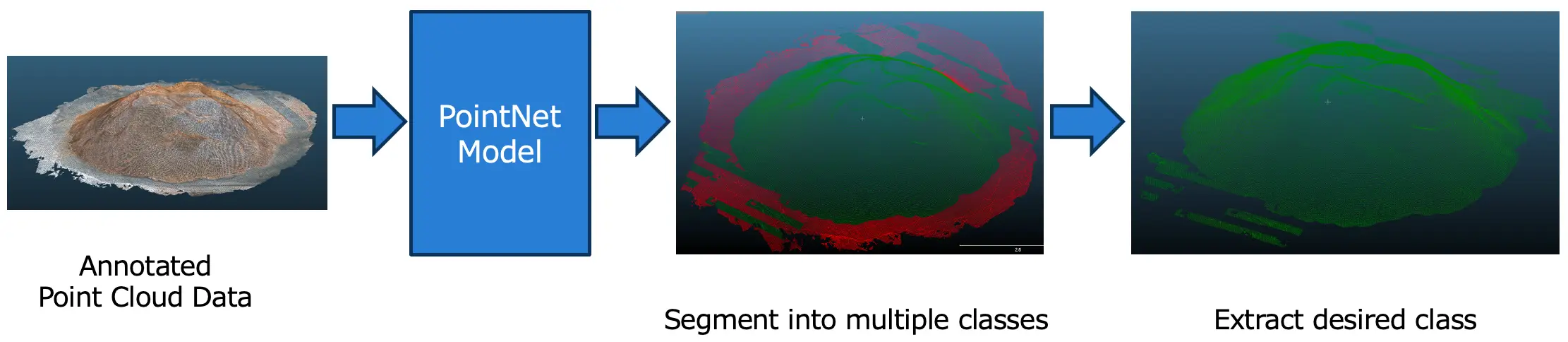 図12:セグメンテーション
図12:セグメンテーション
図12は、ターゲットの点と非ターゲットの点のセグメンテーションを示したものです。上図の2つの色は、ターゲットと非ターゲットのセグメントを表しています。赤色は、床や壁などのポイントを含む非ターゲット部分で、緑色はオガ粉の点を含むターゲット部分を表します。AIモデルのセグメンテーション性能を計測する指標としてmIoUを用いたところ、テストデータの平均mIoUは86.95%となりました。
外れ値除去
セマンティック・セグメンテーションとターゲット・クラスのデータ抽出の後、異常値を除去する必要があります。
 図13:外れ値の除去
図13:外れ値の除去
図13は、セグメント化されたターゲットデータの外れ値除去を示すものです。異常値を除去することで、より正確に体積を算出することができようになります。
三角メッシュ
点群から体積を計算することはできないため、点群データをメッシュデータに変換することを考えます。点群データからメッシュデータを作成するには、表面再構成問題を解きます。表面再構成問題はいわゆる不良設定問題であり、完全な解は存在せず、ヒューリスティックな方法でメッシュデータを得ます。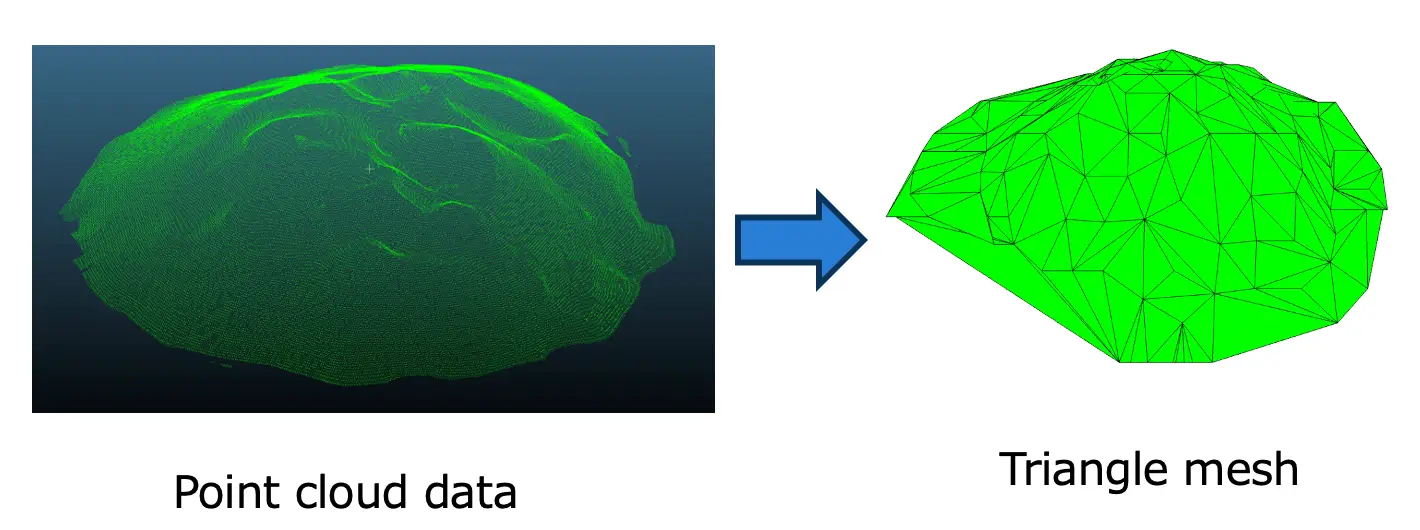 図14:点群からの三角メッシュ
図14:点群からの三角メッシュ
図14は、点群データからメッシュを構築する様子を示しています。メッシュとは、オブジェクトの形状を表す、相互に接続された三角形または多角形の集合です。我々はOpen3D libを使って点群データを三角メッシュに変換しました。
体積計算
Open3Dを使って三角形のメッシュから表面を得ます。この表面から体積を計算する方法はいくつかありますが、その一つが、表面の各三角形の体積をXY平面に対して計算する方法です。そして、すべての三角形の体積を加算して、全体の体積を求めます。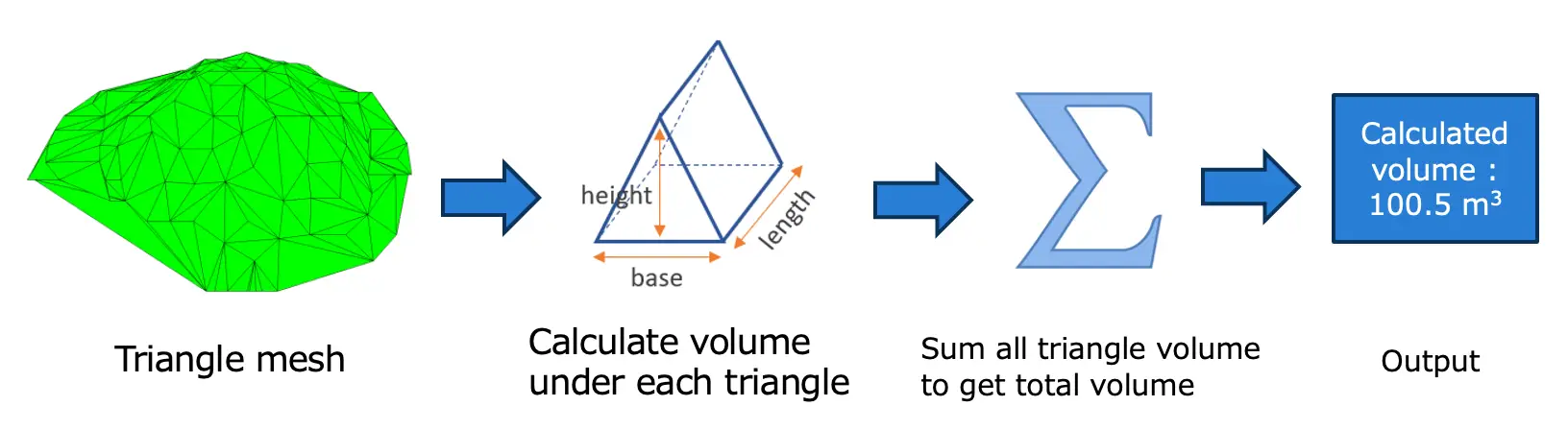 図15:体積計算
図15:体積計算
図15に三角メッシュからの体積計算の流れを示します。この流れに従い、三角メッシュから体積を計算しました。
結果
本実験では、トレーニング用に6ファイル、検証用に1ファイル、テスト用に4ファイル、合計11のオガ粉点群ファイルを使用しました。各ファイルには約30万点のデータが含まれています。モデルのトレーニングとテストにはGCPサーバーを使用しました。
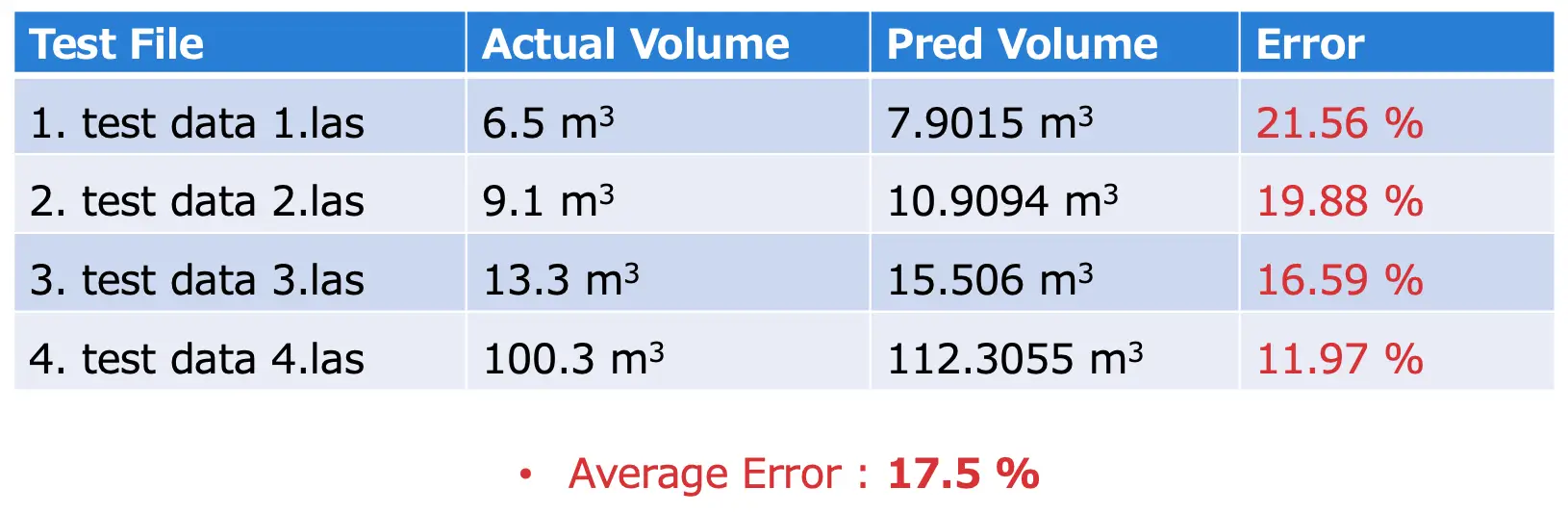 表1 : 実験結果
表1 : 実験結果
表1がその実験結果です。実際の体積と、予測された体積の誤差を示しています。平均誤差は17.5%であり、予測体積が実際の体積よりも大きいことがわかります。これは学習データが少ないため、セグメンテーションの精度が上がらなかったことが原因と考えられます。多くの異常値や偽陽性点が存在し、三角メッシュを作成する際にこれらの外れ値が影響し、より多くの三角メッシュの体積が計算されます。その結果、オガ粉の山全体の体積が増加したものと考えられます。学習データが十分に多ければ、予測される体積は実際の体積にもっと近づくと期待しています。
Webアプリ
Gradioフレームワークを使用して、オガ粉体積計測のためのWebアプリも開発しました。Webインターフェースは2つに分かれており、左側が入力パネル、右側が出力パネルです。
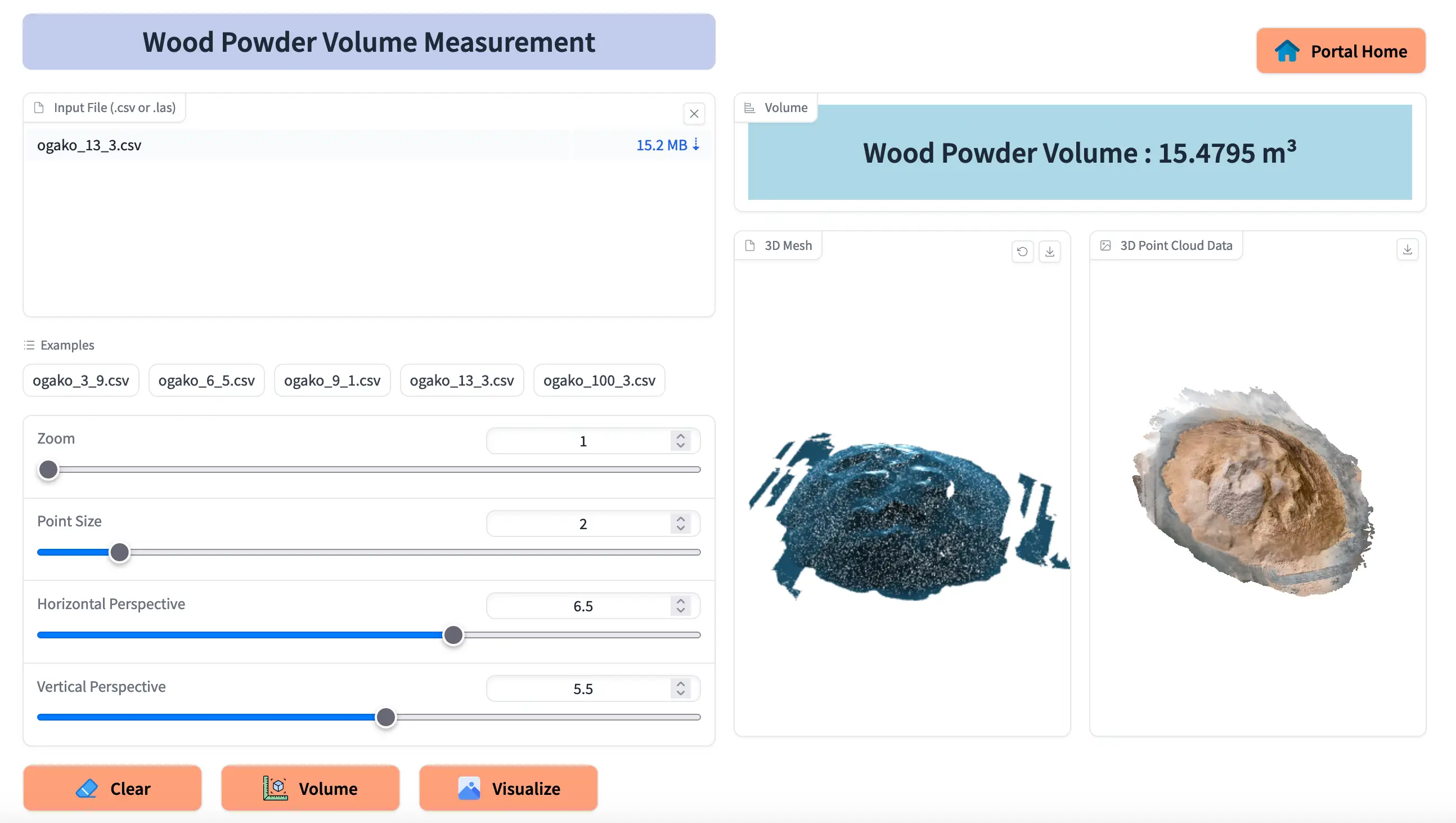 図16:Webアプリ
図16:Webアプリ
図 16 はそのWebアプリの UI です。入力パネルでは、体積を計算したいLASファイルまたはCSVファイルをアップロードできます。また入力パネルにはスライダーが複数あり、入力データの視覚化を変更することができます。出力パネルには、入力データに対して計算された体積が表示されます。また、入力データを2D画像と3Dメッシュ形式で表示することもできます。
まとめ
今回の検証の主な目標は、点群データからなるオガ粉の体積を計測することでした。点群のセグメンテーションにはPointNetモデルを使用し、対象データをセグメンテーションした後、三角メッシュを作成し、各三角形の体積を測定しました。その後、3次元三角形の体積を合計し、オガ粉全体の体積を求めました。セグメンテーション結果と体積計測結果は非常に良好で、セグメンテーション結果(mIoU)は86.95%でしたが、実際の体積と予測体積の平均誤差は17.5%となりました。これは学習とテストに使用したデータはそれほど多くなかったことが原因と考えられ、より多くのデータがあればモデルの性能と体積計算の精度を向上させることができるでしょう。
このように、調和技研ではAIの社会実装を目指し、日々研究開発を続けています。AIを用いて解決したい課題などありましたら、お気軽にご相談ください。
【参考文献】
- Point Cloud : https://www.dronegenuity.com/point-clouds/
- Triangle volume : https://www.mathpages.com/home/kmath393/kmath393.htm
- Mesh Volume : https://jose-llorens-ripolles.medium.com/stockpile-volume-with-open3d-fa9d32099b6f
- Open3D : https://betterprogramming.pub/introduction-to-point-cloud-processing-dbda9b167534
- PointNet : https://towardsdatascience.com/point-net-for-semantic-segmentation-3eea48715a62
- CloudCompare : https://www.danielgm.net/cc/
- Laspy : https://laspy.readthedocs.io/en/latest/intro.html
- Gradio : https://www.gradio.app/
- Docker : https://www.docker.com/get-started/

記事を書いた人
Md Shafiqul Islam
Hello, my name is Md Shafiqul Islam, and currently I am working as an AI Engineer at Chowa Giken Co. I completed my Master's degree in 2020 from Kyushu Institute of Technology. I joined Chowa Giken in 2023. Here, I was engaged in several research projects focused on 3D point cloud data. I am particularly interested to computer vision and NLP to develop innovative solutions.
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
