

AI Agent Vol.3【Agent の 学習と評価】

前回の記事(AI Agent 第2回 : Agentの4つの要素)では、AI Agentの作成のために考慮すべき構成要素について、「Profile」「Memory」「Planning」「Action」の4つに着目して解説しました。
第3回では、AI Agentのサーヴェイ論文「 A Survey on Large Language Model based Autonomous Agents 」をもとに、AI Agentの学習方法や評価方法について紹介していきます。
第1回~第2回では、主にLLMの能力を上手く活用するためのエージェントアーキテクチャについて紹介しました。
一方で、AI Agentではタスク固有の能力や経験が不足し、アーキテクチャの工夫だけでは不十分であることがあります。
そこで今回の記事では、エージェントに知識や経験を獲得させるための方法について
紹介します。
目次
AI Agentとは(復習)
AI Agentとは、与えられた目標の達成のために自律的に判断および行動ができる人工知能システムのことを指します。LLMsやRAGが、人間による指示に対して単発的に応答するのに対して、AI Agent では目標達成までに必要な過程を自ら推論し、複数のタスクを実行することができます。
LLMを活用したAI Agentは、LLMをコントローラとしてタスク達成のための計画を練りながら、様々なツールを動作させることで、人間のような意思決定能力を獲得しています。
これによって、人間による追加入力を必要とせずに複雑なタスクを実行可能となることが期待されています。
AI Agentの学習方法
LLMの応答能力が不足している場合、目的のタスクや専門知識の補強のために専用のデータセットを使ったFine Tuningや、知識を直接挿入するPrompt Engineeringを用いてLLMを強化する方法が多く用いられます。
一方で、AI Agentの能力が不足する場合にはAgentの学習を想定したアーキテクチャの設計によって能力向上を目指す方法が用いられます。
本章では、AI Agentの能力向上のための学習方法の選択肢について、従来の言語モデルの能力獲得方法に加えてAI Agent固有の戦略について紹介します。
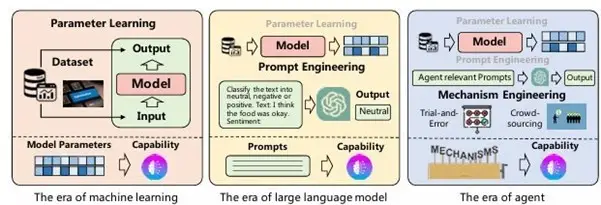
【図1】AI Agentの能力獲得戦略
(A Survey on Large Language Model based Autonomous Agents Fig.4より引用 )
▍Without Finetuning
FineTuningを行うことで、追加知識をLLMに与えることができる一方、本来もっていた汎用性が消失する可能性があります。
また、LLMは非常に多くのパラメータをもつため学習に多くの計算資源と時間を必要とします。これに対してLLMの登場以降では、LLMのFineTuningを行わずに入力やアーキテクチャの調整によってエージェントに追加の知識を与える方法が用いられています。
▍ Prompt Engineering
Prompt Engineeringは、LLMに自然言語によって指示を与え、より効果的な出力を得るための手法です。
追加の知識を与える場合には、タスクの例示やドメイン情報をプロンプトに書き加えることで、LLMが本来持たない知識を使った動作を可能にすることができます。
タスクを分割して推論するCoT(Chain of Thought)や、エージェントの状態を入力に設定するSocialAGI、自己反省を実施するRetroformerといった、様々な手法が提案されています。
▍ Mechanism Engineering
AI Agentには、単一のエージェントだけでなく複数のエージェントを組み合わせて動作させることで、
より効果的な出力を得ることができます。
Mechanism Engineeringは、エージェント同士の構成を工夫することで能力向上を目指す方法です。Mechanism Engineeringによる能力獲得の戦略には、主に以下のようなものがあります。
・Try and error
評価器を組み込み、Agentの行動に対するフィードバックを得ることで、行動の修正を
行う方法です。
・Crowd sourcing
複数の異なるエージェントに同様のタスクを実施させ、複数の回答を比較したうえで
最終的な回答を生成することで能力を高める手法です。
・Experience accumulation
Agentの経験の蓄積によって能力を向上させる手法です。類似タスクの達成経験の活用や
過去ログから生成した知識ベースの利用等が例に挙げられます。
・Self-driven evolution
運用の中でAgentの状態を自己修正することで徐々に能力を向上させる手法です。
報酬関数のフィードバックによって、Agentの目標を設定する手法やAgentの役割/関係を
動的に調整する手法が用いられています。
AI Agentの評価
AI Agentでは、LLM単体の場合と同様に出力の評価を行う必要がありますが、タスクの複雑さや出力/動作の柔軟さから評価が困難であるため、状況に合わせた様々な評価方法が用いられています。
Agentの評価では、データセットの有無やタスクの目的に合わせて、主観的評価と客観的評価が実施されます。
Handcrafting:
手作業によって各Agentの役割を定義する方法です。
性格特性や役割を柔軟に割り当てることができる一方で、扱うAgentが増えるほどに人手による作成コストが多くなってしまう特徴があります。
LLM-Generation:
LLMによってAgentの役割を定義する方法です。
例えば、数ショットの例のみを人手によって作成し、LLMに与えることで類似のプロファイルを作成する方法があります。この方法では、作成コストの削減が可能となる一方で、正確な制御ができず矛盾が生じやすくなる欠点があります。
Dataset-Alignment:
実在の統計データに基づき、プロフィールを作成する方法です。人種/性別/年齢といった
実人間の属性をAgentに与えることで実世界のシミュレーションに用いることができます。
▍主観的評価
主観的評価では、人間の判断に基づいてエージェントの能力を測定します。
この方法は、評価データセットが存在しない場合や、定量的な評価が困難である場合、主に
用いられます。
主観的評価には以下のような方法が考えられます。
Human Annotation:
人手によりAgentの出力を直接採点する評価方法です。
一例として、いくつかの観点についてのスコアを設定し、各モデルを比較する手法があります。
Turing Test:
Agentの出力であるかを人手によって区別できるかを基準に評価する方法です。
評価者がAgentと人間の結果を区別できない場合に、Agentが人間に近い能力を持つと判断
することができ、人間の動作の再現能力を評価指標としています。
近年では、上記の他にLLMを使用した主観評価の研究が増加しており、タスクの達成状況とプロセスをGPTによって評価する手法であるChemCrowや複数のAgentを用いて、討論形式でモデルの評価を行う手法であるChatEvalといった評価指標が提案されています。
▍客観的評価
客観的評価では、評価指標を用いてエージェントの能力を定量的に評価します。
主観的評価とは異なり、エージェントの能力について具体的かつ測定可能な洞察を得ることを目的としています。客観的評価の実施にはいくつかの重要な観点があり、本節では「Metrics」「Protocols」について紹介していきます。
・Metrics
エージェントの効果を客観的に評価するためには適切な評価指標を設計することが重要となります。
評価指標はエージェントの品質を正しく反映し、実世界における人間の感覚と一致するものを用いる必要があります。
主な評価指標には、以下のようなものがあります。
Task success:
タスクの達成度を評価指標とする方法であり、タスクの成功率や報酬関数のスコア、精度等を用います。
Human similarity:
人間の出力との類似度を評価指標とする方法です。
対話の類似性や人間による反応の模倣度合いを指標とすることで、人間の動きをどれだけ再現できるかを評価します。
Efficiency:
タスクの達成過程での推論速度やAgentの対話数に基づき、Agentの効率を評価する方法です。
・Protocols
客観的評価の実施において、どのように評価指標を活用するかにも、いくつかの選択肢が
存在しています。
評価指標の主な活用方法については、以下のようなものがあります。
Real-world simulation:
ゲームやシミュレータ内でのAgentの動きを、タスクの成功率や人間との類似性を用いて
評価する方法です。
この方法を用いることで、現実世界におけるAgentの実用性を評価することが期待されます。
Social evaluation:
Agentにスキル評価のための共同作業や議論能力推定のための討論を行う方法です。
人間の社会性評価と同様の指標で、Agentの社会性を評価することができます。
Multi-task evaluation:
複数のタスクを含むデータセットを利用してタスクの達成率を評価することで、Agentの
汎用能力を測定する方法です。
まとめ
本稿では、AI Agentについての紹介第3弾として、AI Agentの構築手法の最新動向をまとめたサーヴェイ論文である「 A Survey on Large Language Model based Autonomous Agents 」を元に AI Agentの学習方法や評価方法について解説しました。

記事を書いた人
釣部 勇人
理工学専攻の大学院生で、主に言語AIを扱っています。大学では、生成AIを用いた学習支援アドバイスの生成について研究しています。
関連記事

OpenAI Canvas - AIと共同作業を加速する新たな作業空間 -

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
