

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

Google社が提供する「Gemma」は、2024年2月に公開されたオープンソースのLLMです。このモデルは同社がAPIで提供している「Gemini」と同様の研究とテクノロジーから構築された軽量モデルです。今回はこのモデルの概要を説明するほか、精度を検証するために実際にいくつかの質問をしてみました。
目次
 参考: https://ai.google.dev/gemma?hl=ja[1]
参考: https://ai.google.dev/gemma?hl=ja[1]
Gemma の特徴
Gemmaの主な特徴として以下の三つが挙げられています。
• 設計における責任
これらのモデルには包括的な安全対策が組み込まれており、厳選されたデータセットと厳密なチューニングを通じて、責任ある信頼できる AI ソリューションを確保できます。
• 規模において比類のないパフォーマンス
Gemma モデルは、2B と 7B のサイズで優れたベンチマーク結果を達成し、一部の大規模なオープンモデルよりも優れています。
• フレームワーク フレキシブル
Keras 3.0 を使用すると、JAX、TensorFlow、PyTorch とシームレスに互換性があるため、タスクに応じてフレームワークを簡単に選択して切り替えられます。
Gemmaモデルは、複数のサイズが公開されており、モバイルデバイスやノートパソコン等のリソース要件の低い環境を想定した2Bモデルと、デスクトップコンピュータや小規模サーバ等を想定した7Bモデルがあります。特に Gemma 7B モデルは、代表的なオープンLLMである Meta社のLlama2、MistralAI社のMistralのモデルサイズと同様です。
|
Model |
Context-window
|
Size
|
|
google/gemma[2] |
8192 |
2B ~ 7B |
|
mistralai/Mistral[3] |
32768 |
7B, (8x7B, 8x22B MoE) |
|
Meta-llama/Llama2[4] |
4096 |
7B ~ 70B |
Gemma の性能
公式よりGemmaのベンチマークテスト結果が公開されており、Gemmaに近いパラメータ数をもつ既存のオープンLLMである Llama2、Mistralの結果との比較が行われています。結果として、質問応答、推論、数学、コーディングの4タスクにおいて同パラメータ数の既存モデルを上回るスコアが確認されています。また、Gemma 7Bよりもパラメータ数の大きいLlama 2 13Bと比較しても、匹敵もしくは上回る結果となっています。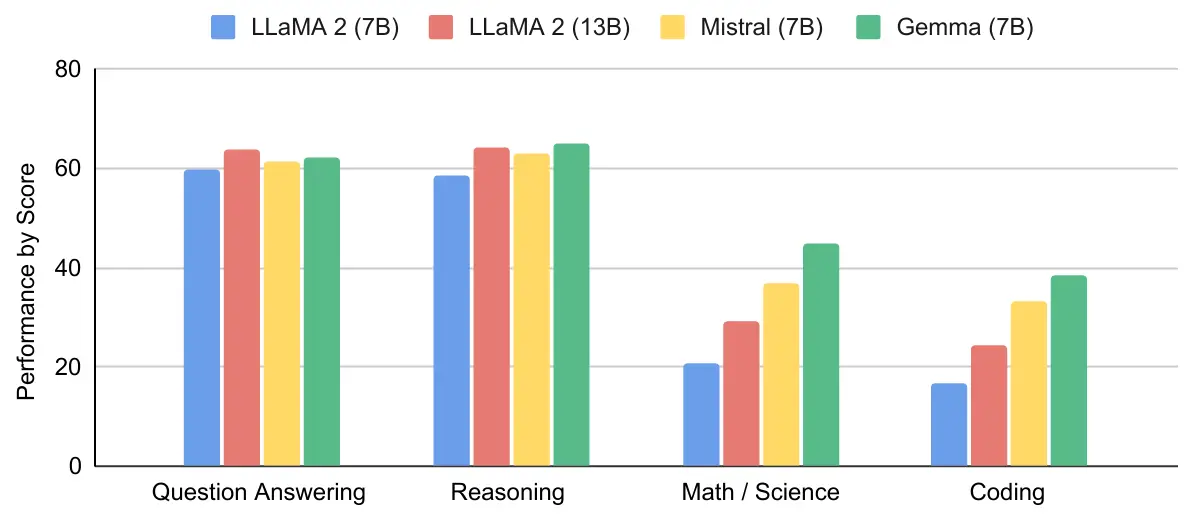
詳細はテクニカルレポート[5]をご確認ください。
Gemma の使い方
「Gemma」はHuggingFace上で公開されています。他のオープンソースモデルと同様にモデル名を指定することで利用できます。ただし、Gemmaは制限モデルであるため利用する際にはHuggingFace上でライセンスに同意して制限を解除する必要があります。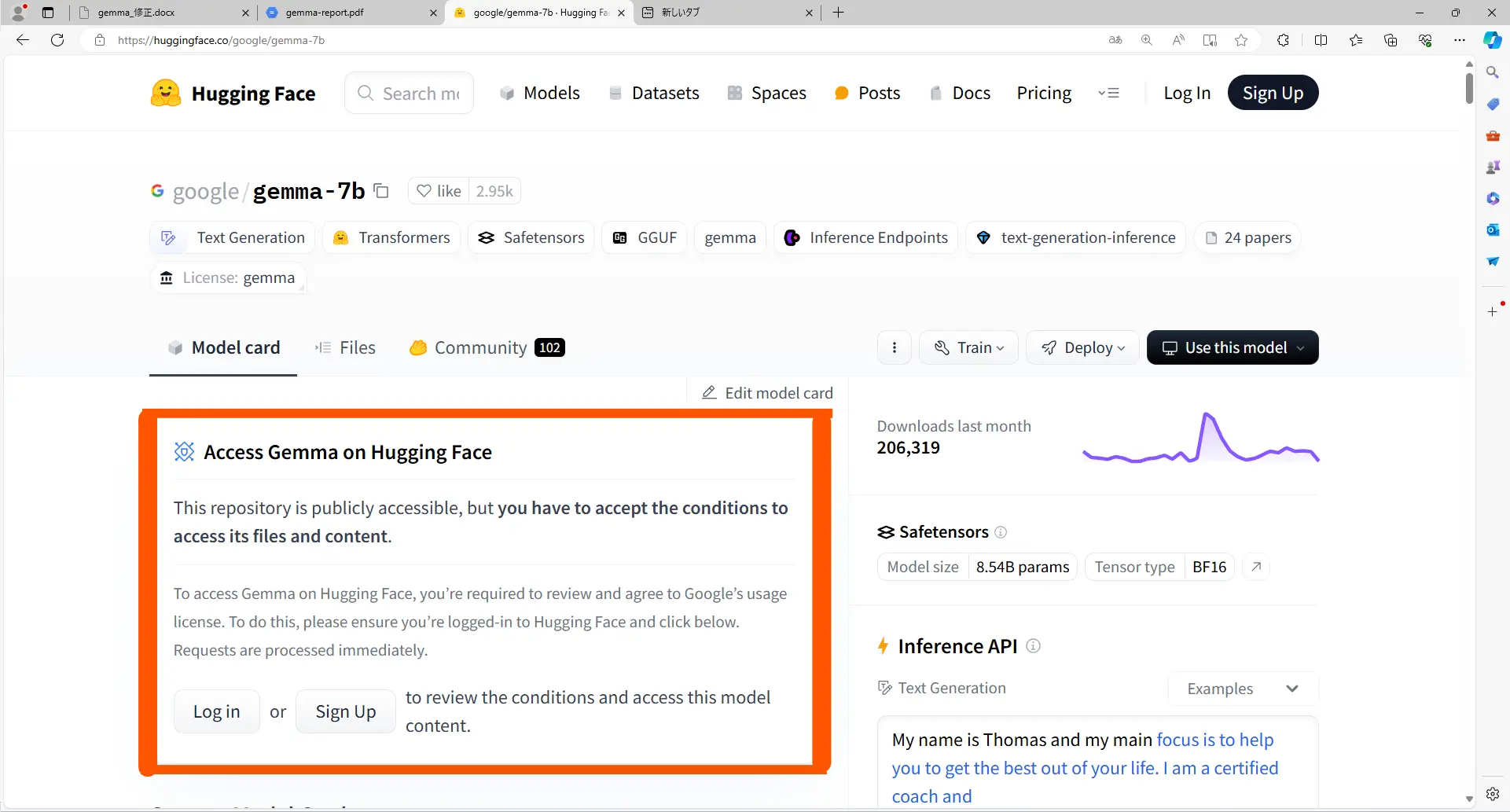
また、実行する際にもHuggingFaceアカウントと紐づける必要があるため、アクセストークンを取得しておきます。アクセストークンはログイン後のユーザアイコン>>Settings >> Access Tokensから取得できます。
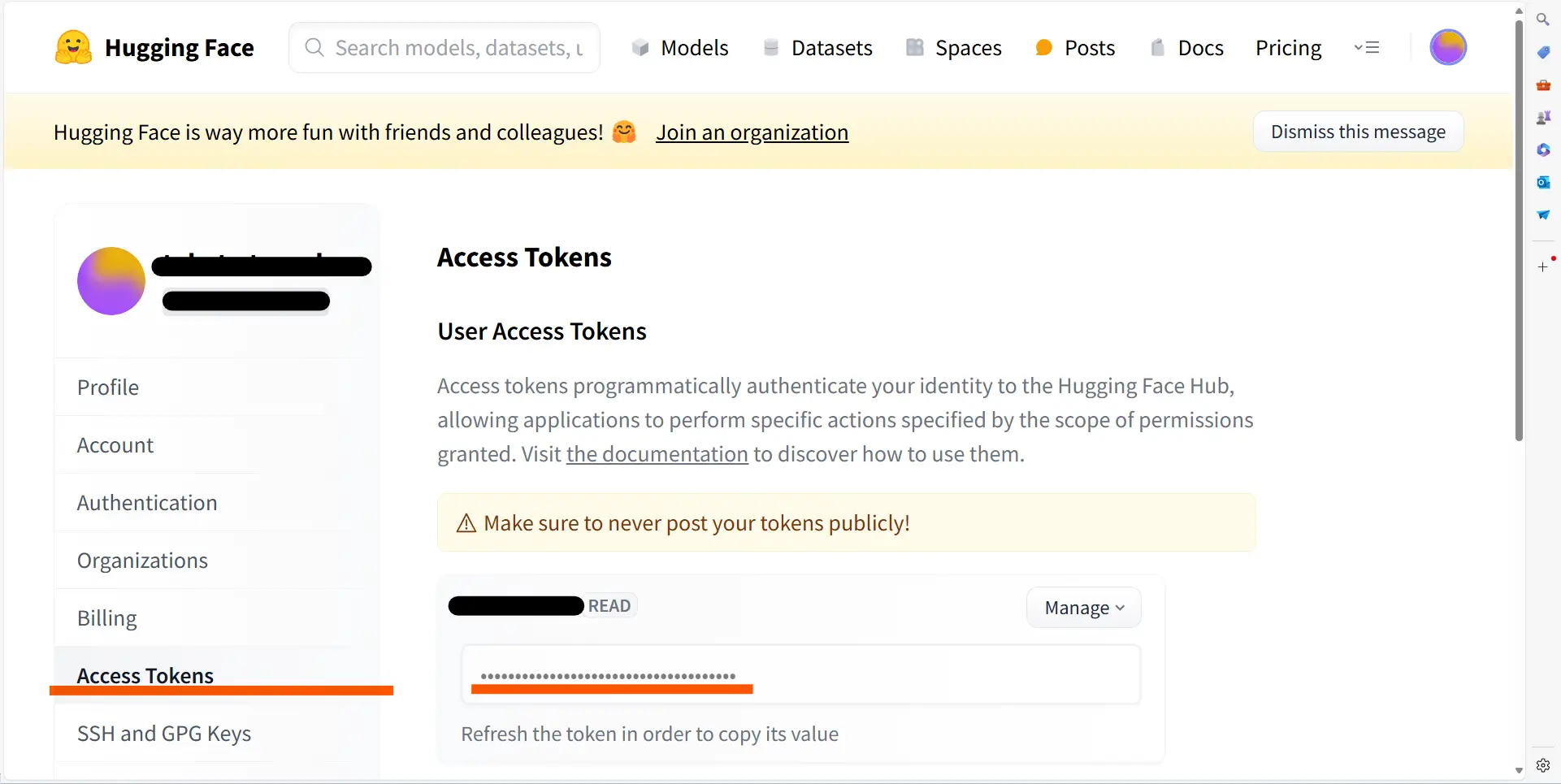
実行
pip install transformers torchモデル名を“google/gemma-7b-it”と指定することで利用できます。また、モデルの読み込み時に先ほど取得したアクセストークンを指定します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-2b-it",
token = “YOUR_ACCESS_KEY”
)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
torch_dtype=torch.bfloat16,
token = “YOUR_ACCESS_KEY”
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))詳細は、公式Documents[6]をご確認ください。
Gemma とOpenAI GPT-3.5 Turboを比較する
いくつかの質問への回答を Gemma と OpenAI 社の GPT-3.5 Turbo に質問し、どのような違いがあるか比較してみましょう。今回は公開されている Gemma モデルのうち instruction tuning が実施されている “google/gemma-2b-it”,“google/gemma-7b-it”を用います。
今回は、以下2つの問題にどのように回答するかを試してみました。
- 心のモデル
- 国語の問題
心のモデル
まずは、登場人物の心の状態を読み取ることができるかの問題を出題します。
以下のプロンプトを実行します。
|
①サリーとアンが部屋で一緒に遊んでいます。 ②サリーはボールをかごの中に入れて部屋を出て行きます。 ③サリーがいない間にアンがボールを別の箱の中に移します。 ④サリーが部屋に戻ってきます。 《問題》サリーはボールを取り出そうとして最初にどこを探しますか? |
それぞれのモデルの生成結果は以下のようになりました。
“Gemma 2B it”
|
①、②
サリーは部屋でボールを取り出す際に、まず部屋の入り口や部屋の他部分をよく確認します。 |
“Gemma 7B it”
|
①
これは、サリーがボールを取り出すために部屋内で最初の場所を確認するため、正解は①です。 |
“gpt-3.5-turbo”
|
サリーは最初にかごの中を探すでしょう。 |
|
Model |
Correct Answer Rate ( /10) |
|
gpt-3.5-turbo |
1.0 |
|
Gemma-2B-it |
0.0 |
|
Gemma-7B-it |
0.0 |
|
Correct-Answer |
- |
こちらの質問は、“かご”を探すが正答です。
GPT-3.5 Turboでは正答できていますが、Gemmaモデルはどちらも誤答になっており、①~④を過程ではなく回答の選択肢と認識しています。試行回数=10の場合の正答率は、Gemmaモデルはともに0.0になっており、すべて誤答になってしまいました。
国語の問題
次に、文章の内容から適切な回答を選択する国語の問題を試してみましょう。
以下のプロンプトを実行します。
|
次の文を読みなさい。 Alexは男性にも女性にも使われる名前で、女性の名Alexandraの愛称であるが、男性の名Alexanderの愛称でもある。 この文脈において、以下の文中の空欄にあてはまるもっとも適切なものを選択肢のうちから1つ選びなさい。 Alexandraの愛称は( )である。 ①Alex ②Alexander ③男性 ④女性 |
それぞれのモデルの生成結果は以下のようになりました。
“Gemma 2B it”
|
①Alex Alexは男性にも女性にも使われる名前で、女性の名Alexandraの愛称である。 |
“Gemma 7B it”
|
答案:①Alex |
“gpt-3.5-turbo”
|
①Alex |
|
Model |
Correct Answer Rate ( /10) |
|
gpt-3.5-turbo |
1.0 |
|
Gemma-2B-it |
0.5 |
|
Gemma-7B-it |
0.6 |
|
Correct-Answer |
- |
こちらの質問は、①(Alex)が正答です。
生成例ではどのモデルも正しく回答できています。試行回数=10の場合の正答率は、OpenAIのGPT-3.5 Turboの正答率1.0に対してGemma-2B-it=0.5, Gemma-7B-it=0.6と低い正答率となりましたが、低パラメータ数のモデルにもかかわらず半数以上は正答できていることがわかります。
Gemma のまとめ
本記事では、Google社が提供するLLMの「Gemma」についてご紹介しました。
今回は2つの質問を試してみましたが、GPT-3.5 Turboよりも劣っている結果となったものの「国語の問題」には50%程度の正答率で回答できています。対して、「心の問題」は全く正答できておらず、タスクによって得意不得意が大きく分かれた結果となりました。選択式の「国語の問題」への正答率が高い点や記述形式の質問である「心の問題」へ選択式で回答してしまっている点から、特に選択式での質問が得意であるのかもしれません。
Gemma 2B は、公開されているオープンLLMの中でも比較的モデルサイズが小さいものとなっていますが、今回の結果の中で Gemma 7B から大きく精度を落とすことはありませんでした。その点から、Gemmaは軽量モデルとして十分に活用できるかもしれません。
【参考文献】
[1]https://ai.google.dev/gemma?hl=ja
[2]https://www.kaggle.com/models/google/gemma
[3]https://mistral.ai/technology/#models
[4]https://llama.meta.com/llama2/

記事を書いた人
釣部 勇人
理工学専攻の大学院生で、主に言語AIを扱っています。大学では、生成AIを用いた学習支援アドバイスの生成について研究しています。
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
