

Langchain+Neo4j で「GraphRAG」を実装してみる

「GraphRAG」は、Microsoft Researchによって提案された知識グラフを利用した新たな検索拡張生成(Retrieval Augmented Generation; RAG)手法です。知識グラフを利用することでRAGの検索部分を改善し、従来のベクトルベースの手法に比べてより関連性の高いコンテンツを取得することができるとされます。
今回はLangchainで紹介されている方法で GraphRAG を実装し、実際にいくつかの質問をして精度を検証していきます。
目次
 参考: GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research[1]
参考: GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research[1]
GraphRAG の特徴
GraphRAGはLLMを用いてドキュメントから知識グラフを構築し、グラフに基づいた検索を行うRAG手法です。この手法では質問応答を行うために、以下の手順をとります。
- ドキュメントから知識グラフを生成
- 知識グラフが保持するエンティティや関係に基づいて質問応答する
GraphRAG の性能
GraphRAGの有用性について Microsoft Researchチームによっていくつかの調査が行われています。この調査では、RAGアプローチを要する質問に対して従来のRAG手法とGraphRAGによる応答を行い、その出力結果を比較しています。調査の結果として、GraphRAGを活用することで二つのエンティティの関係性をつなぐ必要のある質問やデータ全体への総合的な理解を求める質問への回答において従来手法から大幅に改善できるとしています。
また、包括性(Comprehensiveness:質問の暗黙の文脈の枠組みの中での完全性)、多様性(Diversity:提起された質問に対する異なる視点や角度の提供)、エンパワーメント(Empowerment:裏付けとなるソース資料やその他の文脈情報の提供)といった観点においてGraphRAG手法が従来手法に比べて優れたパフォーマンスが得られることが示唆されています。
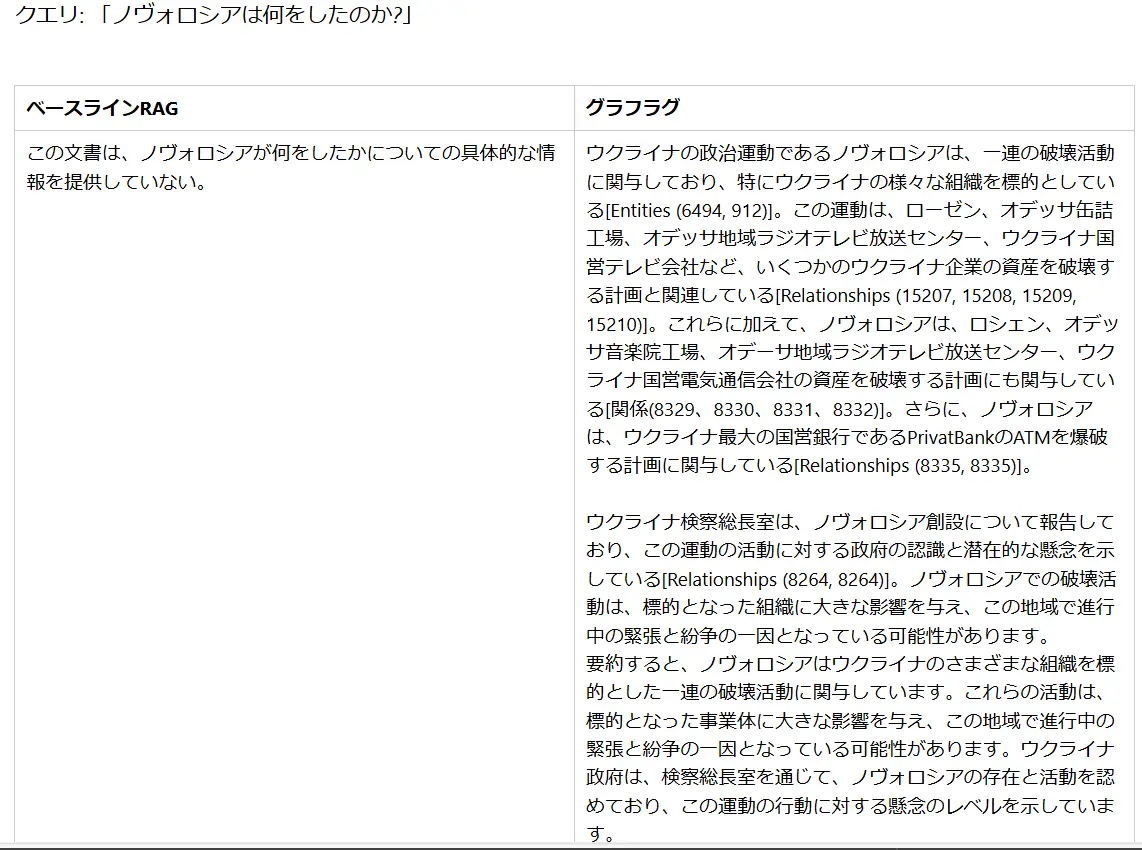
詳細はMicrosoft Researchのレポート[2]をご確認ください。
GraphRAG の実装方法
GraphRAGの知識グラフの生成やグラフベースの質問応答といった手順はLangchainライブラリを活用することで簡単に実装できます。
それでは、実際にGraphRAGを実装してみましょう。
Neo4j DB の構築
GraphRAGを構築する前準備として先にグラフデータベースを作成する必要があります。今回は、Neo4j Aura DBを使ってクラウド上のDBにローカルからアクセスする形式でグラフデータベースを利用しましょう。まずは「Native Graph Database | Neo4j Graph Database Platform[3]」にアクセスし、登録を行います。
次に、コンソールからDBインスタンスを生成し「Downloads and continue」から認証情報を取得します。Neo4j aura にはFreeプランがあり、1アカウントにつき1つのインスタンスを無料で作成できます。この認証情報は実行時に必要になるため、テキストファイルを紛失しないように保管してください。
実行
今回は、実装にLangchain及びNeo4jを、LLMにはOpenAI APIを利用します。そのため、これらに関連するライブラリを読み込みましょう。
pip install --upgrade --quiet langchain langchain-community langchain-openai langchain-experimental neo4j まずは、データセットから知識グラフを作成するためにPDFデータからテキストを読み込みます。また、そのままのテキストでは、一つあたりの入力長が大きくなりすぎるため検索しやすい長さに分割してベクトル化を行います。
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
# demodata/ *.pdf の読み込み
def load_pdf(path: str= "demodata/*.pdf") -> list:
pdf_resources = []
for file in glob.glob(path):
print(file)
loader = PyPDFLoader(file)
pages = loader.load_and_split()
file_text = ''.join([x.page_content for x in pages])
doc = Document(page_content=file_text, metadata={'source': file})
pdf_resources.append(doc)
return pdf_resources
# テキストのチャンク分割
def split_text(docs: list) -> list:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700,
chunk_overlap=100,
)
chunked_resources = text_splitter.split_documents(docs)
return chunked_resources
次に、読み込んだテキストから知識グラフを生成し、Neo4j DBに登録します。このためにはまずNeo4j Aura DBインスタンスの作成時に控えた認証情報やOpenAI API Keyを環境変数に登録する必要があります。以下が登録が必要な環境変数です。
env OPENAI_API_KEY=
env NEO4J_URI=
env NEO4J_USERNAME=
env NEO4J_PASSWORD= 次にLLMによる知識グラフの生成を行います。実装にはLangchainの`LLMGraphTransformer`を用います。詳細な実装方法については公式ドキュメント[4]を参照してください。
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm = ChatOpenAI(
model= $OPENAI_MODEL_NAME
)
graph = Neo4jGraph()
docs = load_pdf()
tgt_chunks = split_text(docs)
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(tgt_chunks)
graph.add_graph_documents(graph_documents)
上記の手順によって、知識グラフを作成できました。Neo4j consoleから作成された知識グラフを確認できます。
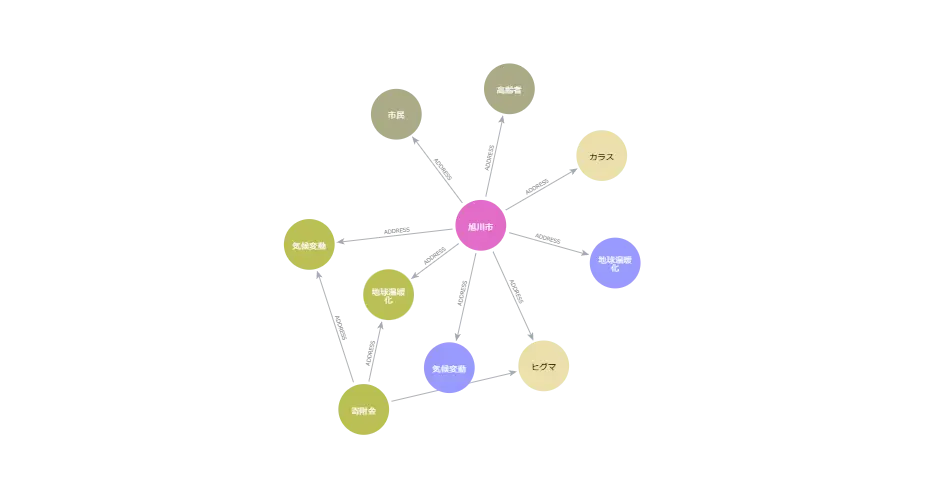
最後に作成した知識グラフに基づいたGraphRAGを構築し、質問応答を行います。
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
graph = Neo4jGraph()
llm = ChatOpenAI(
model=$OPENAI_MODEL_NAME
)
client = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
client.invoke({‘query’: $YOUR_QUESTION})
以上で、GraphRAGを実装することができます。
GraphRAG で質問してみる
先ほど実装したGraphRAGの動作を確認してみましょう。今回は、小説「走れメロス」のテキストデータを利用しました。この内容についての質問をし、どのような応答が得られるのか生成されるクエリや検索結果とともに確認しましょう。また、知識グラフの生成時と質問応答時のそれぞれの時点でLLMを変更した場合にどの程度違いが出るかも合わせて確認してみます。比較対象のLLMにはOpenAIのGPT-4oとGPT-3.5-Turboを用います。
以下が質問への回答例です。それぞれの質問に対する回答を「知識グラフの生成に用いたLLM → 質問応答に用いたLLM」の形式で表記しています。
質問1:メロスとセリヌンティウスの関係を教えて
◆GPT-4o → GPT-4o
Query: cypher MATCH (a:Person {id: 'メロス'})-[r]-(b:Person {id: 'セリヌンティウス'}) RETURN type(r), r
Context:[{'type(r)': '友人', 'r': ({}, '友人', {})}, {'type(r)': '人質', 'r': ({}, '人質', {})}, {'type(r)': '友', 'r': ({}, '友', {})}, {'type(r)': '友', 'r': ({}, '友', {})}, {'type(r)': 'FRIEND', 'r': ({}, 'FRIEND', {})}, {'type(r)': 'TRUSTS', 'r': ({}, 'TRUSTS', {})}, {'type(r)': 'TRUSTS', 'r': ({}, 'TRUSTS', {})}, {'type(r)': 'CLIMBED_TO', 'r': ({}, 'CLIMBED_TO', {})}]
回答:メロスとセリヌンティウスは友人であり、互いに信頼し合っています。
◆GPT-4o → GPT-3.5-Turbo
Query: MATCH (p1:Person {id: "メロス"})-[:FRIEND]->(p2:Person {id: "セリヌンティウス"}) RETURN p1, p2
Context:[{'p1': {'id': 'メロス'}, 'p2': {'id': 'セリヌンティウス'}}]
回答:メロスとセリヌンティウスは関係があります。
◆GPT-3.5-Turbo → GPT-4o
Query: cypher MATCH (p1:Person {id: 'メロス'})-[r]->(p2:Person {id: 'セリヌンティウス'}) RETURN r
Context:[{'r': ({}, '友情', {})}, {'r': ({}, 'FRIEND', {})}, {'r': ({}, 'DISCIPLE', {})}]
回答:メロスとセリヌンティウスの関係は友情、FRIEND、DISCIPLEです。
◆GPT-3.5-Turbo → GPT-3.5-Turbo
Query: MATCH (p1:Person {id: "メロス"})-[:FRIEND]-(p2:Person {id: "セリヌンティウス"}) RETURN p1, p2
Context:[{'p1': {'id': 'メロス'}, 'p2': {'id': 'セリヌンティウス'}}]
回答:メロスとセリヌンティウスには直接の関係はありません。
GPT-4oによって生成されたクエリは人物であるメロスとセリヌンティウスの関係を検索しています。特に「GPT-4o → GPT-4o」では友人や人質、信頼関係等の様々な属性が取得できています。一方で、GPT-3.5-Turboによるものでは人物側を取得するものとなっており正しく検索ができていません。また、「GPT-4o → GPT-4o」 と「GPT-3.5 Turbo → GPT-4o」を比較すると、得られる属性の数が大きく異なり、GPT-4oによって生成された知識グラフを活用したものがより多くの属性を保持しているように見えます。
今回活用したデータはすべて日本語ですが、すべてのモデルに共通して知識グラフには日本語と英語が混ざった状態で登録されているようです。
質問2:メロスはどんな場所を通りましたか
◆GPT-4o → GPT-4o
Query: cypher MATCH (p:Person {id: 'メロス'})-[:TRAVELED_TO]->(pl:Place) RETURN pl
Context:[{'pl': {'id': '村'}}, {'pl': {'id': '野'}}, {'pl': {'id': '森'}}, {'pl': {'id': '隣村'}}]
回答:メロスは村、野、森、隣村を通りました。
◆GPT-4o → GPT-3.5-Turbo
Query: MATCH (p:Person {id: "メロス"})-[:TRAVELED_TO]->(place:Place) RETURN place;
Context:[{'place': {'id': '村'}}, {'place': {'id': '野'}}, {'place': {'id': '森'}}, {'place': {'id': '隣村'}}]
回答:村、野、森、隣村
◆GPT-3.5-Turbo → GPT-4o
Query:cypher MATCH (m:Person {id: 'メロス'})-[:VISITS]->(l:Location) RETURN l
Context: [{'l': {'id': '宴席'}}, {'l': {'id': '羊小屋'}}]
回答:宴席、羊小屋を通りました。
◆GPT-3.5-Turbo → GPT-3.5-Turbo
Query:MATCH (p:Person {id: 'メロス'})-[:入る]->(pl:Place) RETURN pl
Context:[{'pl': {'id': '王城'}}]
回答:王城を通りました。
知識グラフの生成をGPT-4oで行ったものではメロスと場所の関係がTRAVELED_TOである情報を取得するクエリが生成されており、「通ったか」を「TRAVELED_TO」と置き換えて検索されています。一方で、GPT-3.5 Turboによるものでは、「VISITS」や「入る」と変換されているようです。結果として様々な場所が取得され、それに基づいた回答が得られています。
GraphRAG のまとめ
本記事では、知識グラフを活用したRAG手法であるGraphRAGについてご紹介しました。
GraphRAGを活用することで知識グラフに沿って回答できることが確認できました。GraphRAGでは、ベクトルベースの検索に比べて関係性を正しく認識しやすくなるため、複数のマニュアルの関係性を考慮する必要がある複雑な質問への対応ができるようになる可能性があります。
質問文から関連する単語をもつエンティティについて日本語、英語を問わず検索が行われています。LLMによる違いの点では、質問応答をGPT-3.5-Turboによって実施した際に、質問1のように適切な検索クエリを生成できない場合がありました。知識グラフの検索クエリどちらも重要な要素ですが、知識グラフは生成後に人手によって整備することも可能ですが、クエリの生成は適切に行われなければ検索を行うことができません。そのため、質問応答側のLLMはできる限りパフォーマンスの高いLLMを活用すべきかもしれません。
今回用いたデータはすべて日本語であるにもかかわらず、英語で知識グラフに登録されている情報が多く存在しています。また、「友情」「FRIEND」のように同一の意味を持つ単語が別々に保存されているケースも多くありました。これらは、最終的な応答を生成するうえでノイズとなる可能性があります。こういった知識グラフの生成時のノイズを削減できるようにプロンプトを工夫することで、より精度よく検索が行えるようになるかもしれません。
【参考文献】
[1]GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research
[2]GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research

記事を書いた人
釣部 勇人
理工学専攻の大学院生で、主に言語AIを扱っています。大学では、生成AIを用いた学習支援アドバイスの生成について研究しています。
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
