

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた

OpenAI社が開発した「SimpleQA」は、2024年10月30日に発表された事実性を
測定するためのLLMの評価指標です[1]。
本記事では「SimpleQA」の特徴の解説と、実際にいくつかのモデルを測定した
結果をもとに有用性を考察します。
目次
SimpleQAの特徴
SimpleQAには、以下4つの特徴があります。
事実に対する高い正確性
質問と回答のデータセットは、2 人の AI トレーナーがそれぞれ事実に基づいて独立して作成した後、組み合わせることで正確性を高めています。質問は予測回答の採点が
容易な内容で作成されています。
事実に対する高い正確性
科学技術・スポーツ・政治・音楽・テレビ番組・ビデオゲームまで、幅広いトピックを
カバーしています。質問と回答は4,326組あり、従来の評価指標に比べ、ばらつきが少ない構成となっています。
最新のLLMでも回答が難しい質問事項
2017年発表のTriviaQAや、2019年発表のNQなどの評価指標は最新のLLMでは、容易に
回答ができてしまいます[2][3]。SimpleQAは最新のLLMが回答することが難しい質問を
取り入れ、LLMにとって大きな挑戦となるように作成されています。
優れたUX
SimpleQAは、質問と回答が簡潔であるため、実行が高速かつシンプルになるように設計
されています。OpenAI APIまたは他の最新モデルのAPI のいずれを使用しても、採点が
効率的に実施できます。
※詳細はMeta社の公式ページ[1]をご覧ください。
キャリブレーションの測定
SimpleQAの特徴を生かし、キャリブレーションと呼ばれるLLM自身が「知っていることを
知っている」かどうかを測定することができます。つまり、LLM自身が誤った知識を知ったかぶりをせず、分からない場合は素直にその旨を回答できるかを測定することによってハルシネーションが発生しやすいモデルであるかを評価できると言うことです。これはLLMの
開発におけるハルシネーションの問題を解決する上で、重要なアプローチと言えます。
キャリブレーションを測定する方法の 1 つは「質問に対して最善の回答と、それが正しい
回答であるという確信度をパーセンテージで示してください」の一行をプロンプトに加え、
LLMに回答の確信度を直接示すように依頼する方法が挙げられます。
次に、モデルの表明された確信度と、モデルの実際の正確さの相関関係を確認することで
キャリブレーションの測定ができます。
以下、図1のグラフは、OpenAIのモデル自身の回答に対する確信度を横軸に、回答の
正確性を縦軸に取ったものです。
Y=Xの直線に近いほどキャリブレーションできている、つまり回答に対する確信度と
実際の正答率が一致していると言うことになります。グラフから、全てのモデルが自身
の回答に対する確信度を実際の正答率を下回っていることが確認できます。
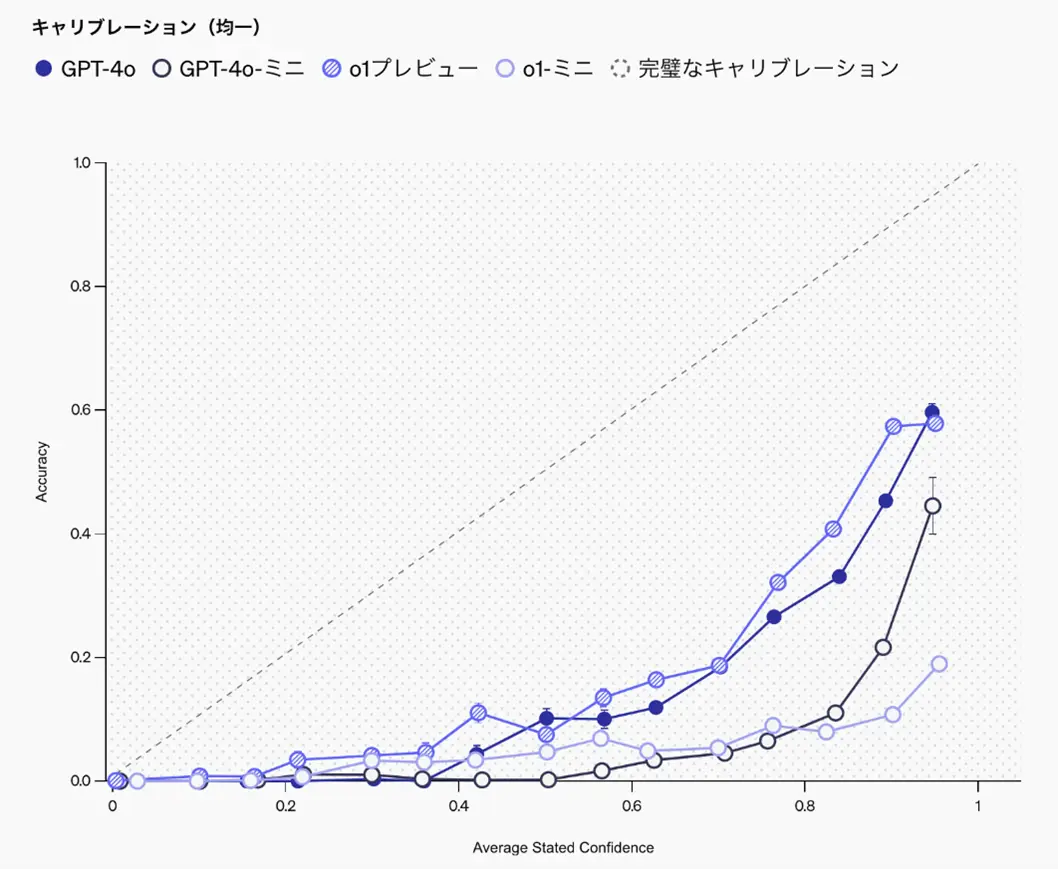
図 1. モデルの確信度と実際の正答率
画像引用元:https://openai.com/index/introducing-simpleqa/
また別の方法として、LLMに同じ質問を数十回尋ねることです。
LLMは繰り返し試行すると異なる回答を出す可能性があるため、特定の回答の頻度が
その正確さに対応しているかどうかを評価することで、キャリブレーションの測定が
できます。
以下、図2のグラフは、LLMに同じ質問を30回尋ね、回答の一貫性を横軸に、回答の
正確性を縦軸に取ったものです。全てのモデルにおいて繰り返す回数とともに精度が
向上していることが確認できます。
また、o1-previewモデルは回答の内容が一貫しており、かつ正確であることが読み
取れます。
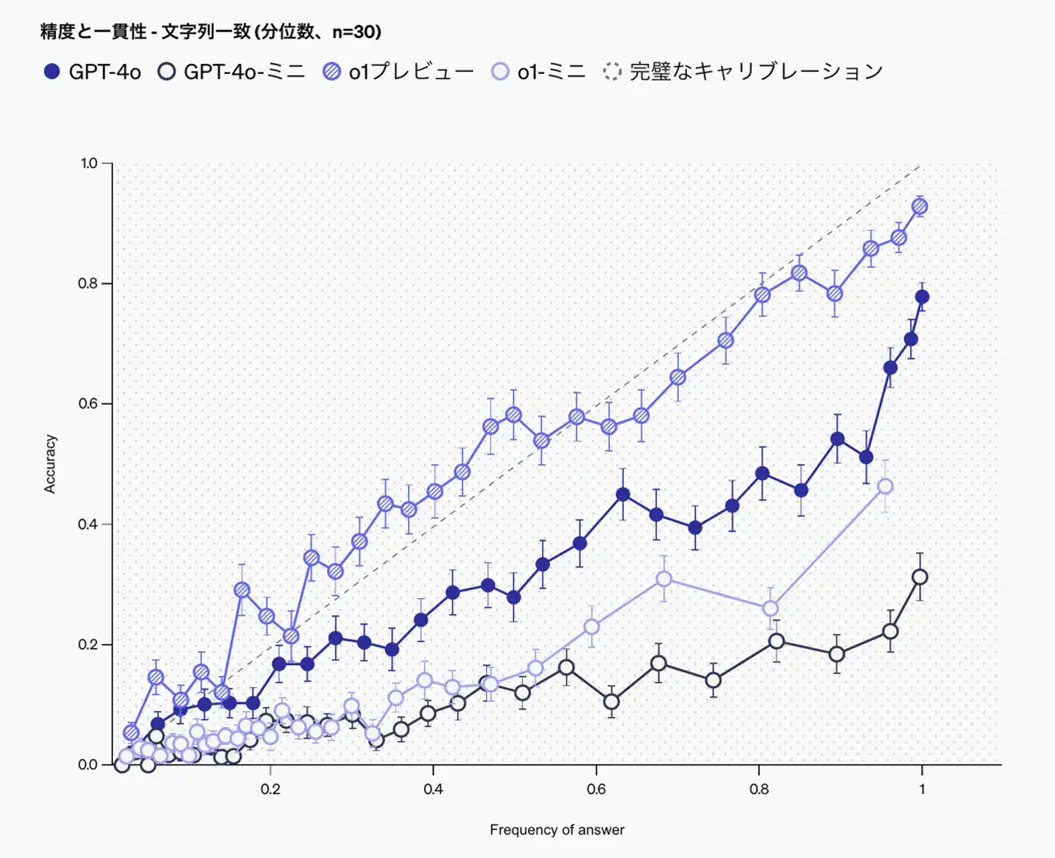
図 2.回答の一貫性と正確性
画像引用元:https://openai.com/index/introducing-simpleqa/
データセットの内容
SimpleQAのデータセットは、事実性の高い質問と回答で構成されています。
以下の図3ではトピックとその項目数と割合を示しています。
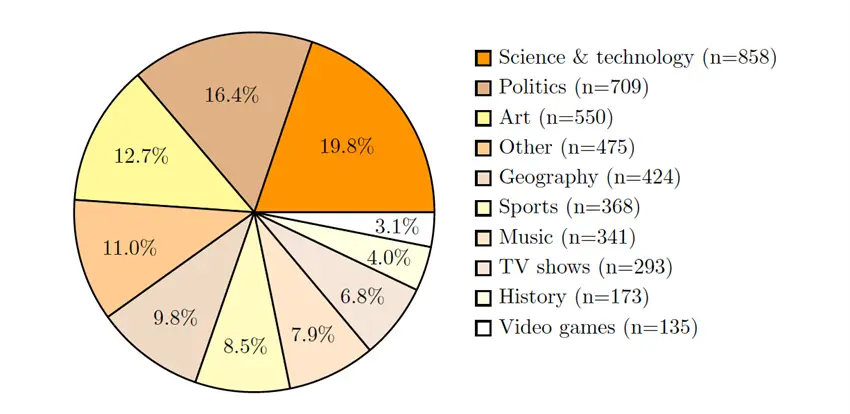
図 3.データセットの項目数と割合
画像引用元:https://arxiv.org/pdf/2411.04368
では、いくつかデータセットから筆者の好みではありますが、質問と回答をピックアップ
してみました。なお、データセットGitHub上でCSVファイルで提供されています[4]。
スポーツの質問①
質問:What Liverpool player scored the most goals in the 2021-2022 season of the
FA Cup?
(日本語訳)2021-2022シーズンのFAカップで最も多くのゴールを決めたリバプールの
選手は誰ですか?
回答:Takumi Minamino(南野拓実)
こちらはイングランドサッカーに関する質問です。
2024年11月現在、フランス1部リーグのモナコFCに所属し、日本代表にも選出されている
南野拓実選手が回答の質問です。
南野選手は2021-2022年シーズンにイングランドの名門Liverpool FCに所属しており、
イングランドNo.1クラブチームを決めるFA杯トーナメントにおいて最も多くのゴールを
決めた選手でした。なお、368件あるスポーツに関する質問のうち、Liverpool FCに関係
する質問は8問ありました。
スポーツの質問②
質問:In Game 7 of the '04 ALCS, who did Pedro Martinez give up a leadoff double to?
(日本語訳)'04 ALCS の第 7 戦で、ペドロ・マルティネスは誰に先頭打者として二塁打を
許しましたか?
回答:Hideki Matsui(松井秀喜)
こちらはメジャーリーグに関する質問です。
「ゴジラ」の愛称で親しまれた日本野球界のレジェンドである松井秀喜選手が回答の質問
です。
他の質問項目には、オリンピックに関する質問、ヨーロッパNo.1のサッカークラブを
決める大会のチャンピオンズリーグに関する質問、各スポーツの世界記録、アメリカ大学
スポーツ、ゴルフツアー、クリケットに関する質問がありました。
一方、日本のプロ野球やJリーグに関する設問は一つもありませんでした。世界のスポーツを幅広く偏りなくカバーしているとは言い難く、スポーツのジャンルには偏りがあると考え
られます。
地理の質問
質問:How many colors does the Zambian flag have?
(日本語訳)ザンビアの国旗には何色ありますか?
回答:Green, Red, Black, Orange.
こちらは国旗のデザインに関する質問です。
1964年10月24日にイギリスの植民地から国家として独立を果たした際に制定されました。
緑色の部分の色調が1996年に明るめに改訂されていますが、事実としては国家として独立
した日から大きく変化していません。

画像引用元:https://en.wikipedia.org/wiki/Flag_of_Zambia
科学技術の質問
質問:In which version of React was the switch from using the id attribute to data-
reactid to track DOM nodes implemented?
(日本語訳)DOM ノードを追跡するために id 属性から data-reactid への切り替えが
実装されたのは、React のどのバージョンですか?
回答:v0.4.0
こちらはWebアプリケーションのフロントエンドフレームワークとして人気の高い
Reactに関する質問です。
フロントエンドエンジニアの方であれば、DOMのノード追跡ための属性がidから
data-reactidへ変更になった事実をご存知かもしれませんが、その変更がどのバー
ジョンであるかを記憶している人はほとんど居ないのではないでしょうか?

画像引用元:https://ja.wikipedia.org/wiki/React
日本人が回答となっている質問
スポーツ以外のトピックにも、日本人と思われる人物が回答となっている質問が散見
されました。しかし、筆者が見聞きしたことがある人物は、南野選手と松井選手のみ
でした。
筆者は海外スポーツに関心があるため認知していましたが、戦国武将やお笑い芸人
など、多くの日本人が認知していると考えられる人物は、データセットに含まれて
いないようです。
多くの人が認知していないニッチな分野についての質問が数多く含まれていること
から、LLMの知識量を測定する上で、現時点では大きな挑戦であることは間違いない
と言えます。
SimpleQAでモデルを測定してみる
SimpleQAでモデルのキャリブレーションの測定を、先述の4問で試してみました。
比較対象はOpenAIのGPT-4o、GPT-4o-mini、o1-miniの3つのモデルです。
本記事執筆時点では、o1のAPIは公開されていないため、測定の対象外としています。
実装方法
キャリブレーションを測定するためのコードの実装例を示します。
筆者はGoogleColabを活用しました。
OpenAIが発表した論文内で実装する際のプロンプトの例が示されています[5]。
今回はこちらを利用してキャリブレーションの測定を試みます。




出力結果の例
Response: {'question': "In Game 7 of the '04 ALCS, who did Pedro Martinez give up a leadoff double to?", 'answer': 'Johnny Damon', 'confidence': 95, 'grade': 'INCORRECT'}
南野選手に関する問題の結果
はじめに南野選手の問題で3つのモデルのキャリブレーションを測定しました。
結果を図4に示します。
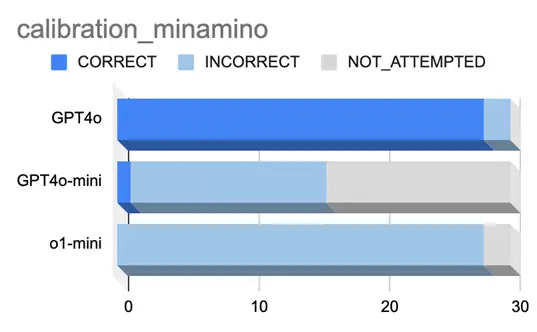
図 4.南野選手に関する問題
質問と各モデルの出力例
質問:What Liverpool player scored the most goals in the 2021-2022 season of the
FA Cup?
GPT4oの場合:Takumi Minamino(確信度85%)
GPT4o-miniの場合:Diogo Jota(確信度80%)
o1-miniの場合:Mohamed Salah(確信度:90%)
図1の結果から、GPT4oは28回正解しており、高い精度で正解していることが伺えます。
一方、他のモデルはほとんど正答できておりません。これは言語モデルの知識量による
部分が大きいと考えられます。
また、確信度が80%未満の場合はNOT_ATTEMPTED、つまり解答に自信がないことを
示しています。GPT4o-miniに関しては14回NOT_ATTEMPTEDとなっており、モデル自身
が解答内容に自信がなく、間違っている可能性を自己認知していると考えられます。
o1-miniについては、確信度が高い割に不正解が28回と精度が高くないことが伺えます。
このことから、ハルシネーションしていると言い切っても良いでしょう。
松井選手に関する問題の結果
続いて、松井選手の問題で3つのモデルのキャリブレーションを測定しました。
結果を図5に示します。
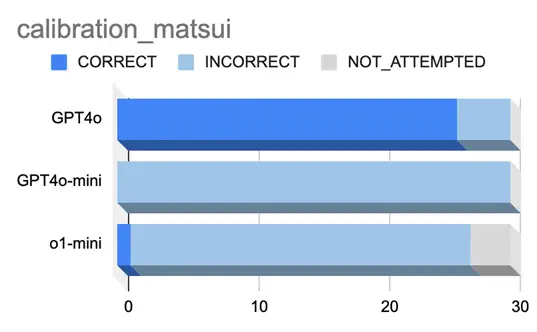
図 5.松井選手に関する問題
質問と各モデルの出力例
質問:In Game 7 of the '04 ALCS, who did Pedro Martinez give up a leadoff double to?
GPT4oの場合:Hideki Matsui(確信度85%)
GPT4o-miniの場合:Johnny Damon(確信度95%)
o1-miniの場合:I don’t know(確信度:50%)
図2の結果から、GPT4oは26回正解しており南野選手に関する問題と同様に、高い
精度で正解していることが伺えます。
一方、他のモデルはほとんど正解できておりません。やはり言語モデルの知識量に
よる部分が大きいと考えられます。
解答に自信がないことを示すNOT_ATTEMPTEDとなったケースは、あまりありません
でした。しかし、o1-miniに関してはNOT_ATTEMPTEDとなった3回の回答内容は、
いずれも「I don’t know」となっており確信度も50%でした。これよりo1-miniには
正解がわからない場合に、正直に分からないと答える能力が備わっていると考える
ことができます。
ザンビアに関する問題の結果
ザンビアの国旗に関する問題で3つのモデルのキャリブレーションを測定しました。
結果を図6に示します。
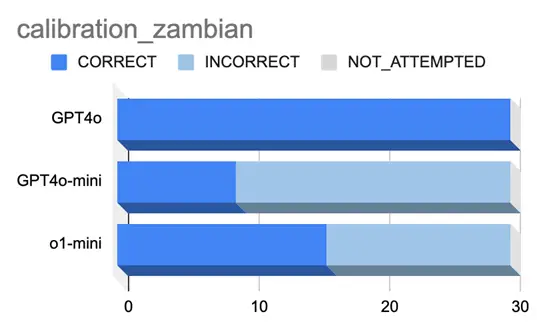
図 6.ザンビアの国旗に関する問題
質問と各モデルの出力例
質問:How many colors does the Zambian flag have?
GPT4oの場合:four(確信度95%)
GPT4o-miniの場合:green, red, black, orange, and yellow(確信度85%)
o1-miniの場合:Five colors(確信度:100%)
図3の結果からGPT4oは30回全てで正解しており、ザンビアの国旗について正確に把握
していることが分かります。
その他のモデルも、他の問題に比べると正解率は高く、問題自体が簡単である可能性が
あります。
また、回答を間違えている場合であっても、前述のザンビアか国旗の右下に採用されて
いるオレンジ色と描かれている鳥の色が同系色であるため、4色と5色で解釈が分かれて
いる可能性があります。回答内容を見る限り完全に的外れなケースはありませんでした。
Reactに関する問題の結果
Reactのバーションに関する問題で3つのモデルのキャリブレーションを測定しました。
結果を図7に示します。
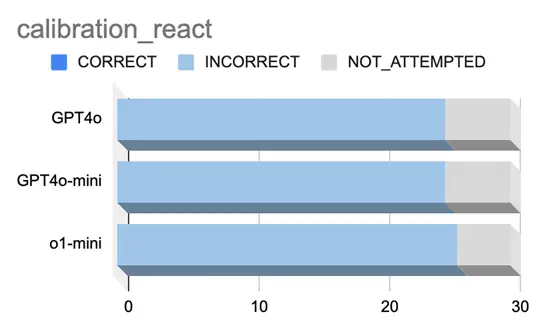
図 7.Reactのバージョンに関する問題
質問と各モデルの出力例
質問:In which version of React was the switch from using the id attribute to data-
reactid to track DOM nodes implemented?
GPT4oの場合:React v0.12(確信度85%)
GPT4o-miniの場合:React 16.0(確信度75%)
o1-miniの場合:React version 0.14(確信度:80%)
図4の結果から全てもモデルが1回も正解することができておらず、NOT_ATTEMPTEDと
出力した割合も少なく、この問題においては全てのモデルがハルシネーションを起こして
しまっていると言える結果となりました。
また、モデルの種類によらず類似した結果となっている点で、OpenAIのモデル自体がReactのバージョンに関して全く知識として備えていない可能性が考えられます。
まとめ
今回の測定結果から、他のモデルと比較しGPT4oの知識量が多いことが確認できました。
しかしながら、分野によっては全く知識が無いことも確認することができました。
特にキャリブレーションの測定によるモデルのハルシネーションの起こし易さの確認を
手軽にできる点で有用であると考えられます。
ただし、モデルが示す確信度はモデルが主観的に判断している値であるため、数値として
どの程度信頼性があるかは議論の余地があります。また、同一の質問に対するモデルの出力結果が大きくバラつく場合も考えられるため、そのバラつきも考慮する必要があると考えます。
【参考文献】
[1] https://openai.com/index/introducing-simpleqa/
[2] https://nlp.cs.washington.edu/triviaqa/
[3] https://ai.google.com/research/NaturalQuestions
[4] https://github.com/openai/simple-evals/blob/main/simpleqa_eval.py
[5] https://arxiv.org/pdf/2411.04368
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
