

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年12月、Googleから新しいLLMモデルの「Gemini 2.0 Flash」が発表されました。
このモデルは Gemini 1.5 Pro と比較して2倍の応答速度を実現し、コード生成や数学問題
などのほとんどのベンチマークで評価の向上が見られています。また、音声や画像による
新しいマルチモーダル出力機能も導入されます。
今回の記事では、この「Gemini 2.0 Flash」にいくつかの質問を提示し、同社の他モデル
との違いを比較していきます。
目次
Gemini 2.0 Flashの概要
Gemini 2.0 Flash は現在、試験運用版としての「Gemini 2.0 Flash Experimental」が公開
されています。
Gemini 2.0 Flash Experimental は Google AI Studioおよび Vertex AIの Gemini API を介して、開発者向けの実験モデルとして提供されており、マルチモーダル入力とテキスト出力が利用できます。
また、テキスト読み上げやネイティブ画像生成(外部の画像生成ツールや別のAIモデルに
依存せず、内部機能として画像生成を行う)機能もありますが、こちらは早期アクセス限定で、現在は公開されていません。これらの機能は近日提供予定となっています(2025年1月
時点)。
※本記事執筆後の2025年2月5日に「Gemini 2.0 Flash」 の正式版が公開されています
Gemini 2.0 Flash Experimentalの性能評価
Google によると、Gemini 2.0 Flash Experimental は、主要なベンチマークで Gemini 1.5
Proを上回るパフォーマンスを発揮し、2倍の応答速度(TTFT: Time To First Token: 最初のトークンを出力するまでの時間)を実現したとしています。
Google が公開した、ベンチマークによる Gemini モデルの性能評価の結果は、 以下(表1)のようになっています。
(表1)主要なベンチマークによる Gemini モデルの性能評価
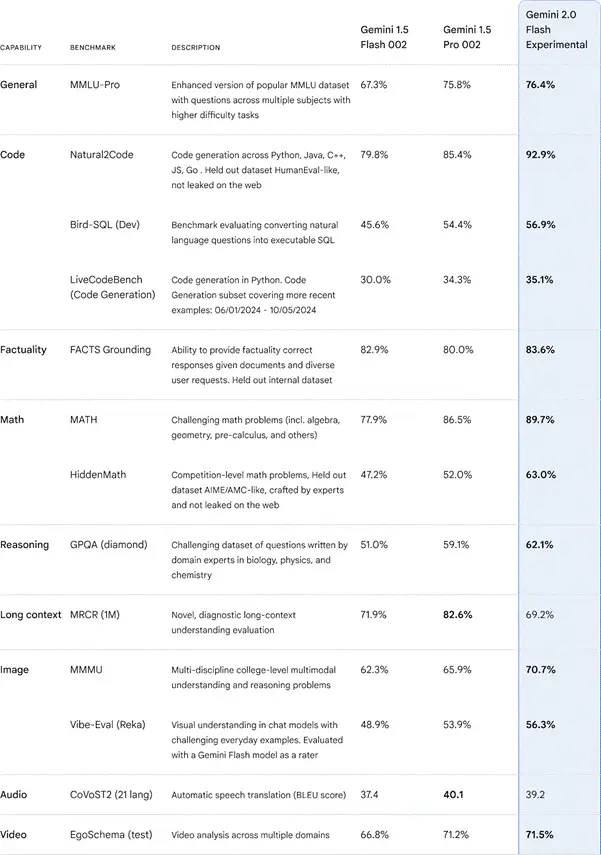
https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024 より引用[1]
表1 によると、一般的なタスク以外にも、コード生成・数学問題・画像推論などの様々な
タスクにおいて、Gemini 1.5 シリーズを上回る性能を示しましたが、長文要約など一部ではGemini 1.5 Pro に劣る結果となっています。
Gemini 2.0 Flash Experimentalの使い方
Gemini 2.0 Flash Experimental は 「Google AI Studio」からAPIキーを取得することで
利用することができます。
なお、APIキーの取得と使用に関して、料金は発生しません(2025年1月時点)。
まず、Google AI Studio[2] にアクセスし、Google アカウントでログインします。
図1 Google AI Studio の画面
次に左上の「Get API key」の画面から「APIキーを作成」をクリックし、APIキーをコピー
します。作成したAPIキーは Google Cloud で確認・管理できます。
図2 APIキーの作成画面
その後、自分の開発環境にAPIキーを設定することで、Gemini 2.0 Flash Experimental を
利用できます。
本記事では開発環境としてGoogle Colabratory の無料版を使用しました。最初に APIを
使用するためのライブラリを、以下のコマンドでインストールします。

次にライブラリをインポートして、以下のコードで APIキーを設定します。

Gemini 2.0 Flash Experimental を使用した応答は、今回以下の関数で実装しました。
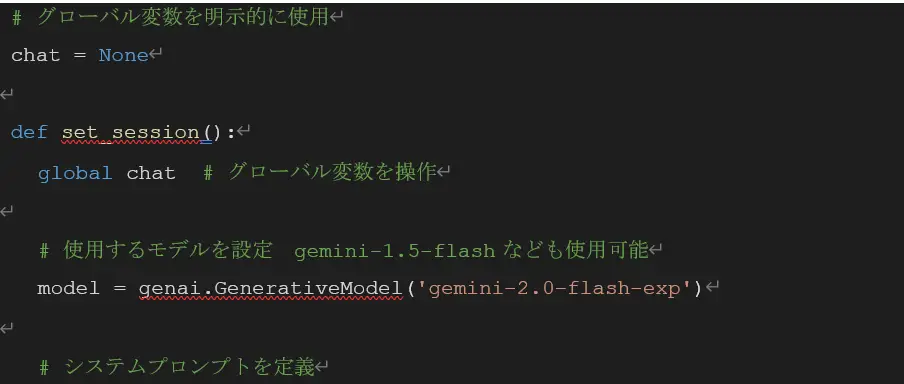
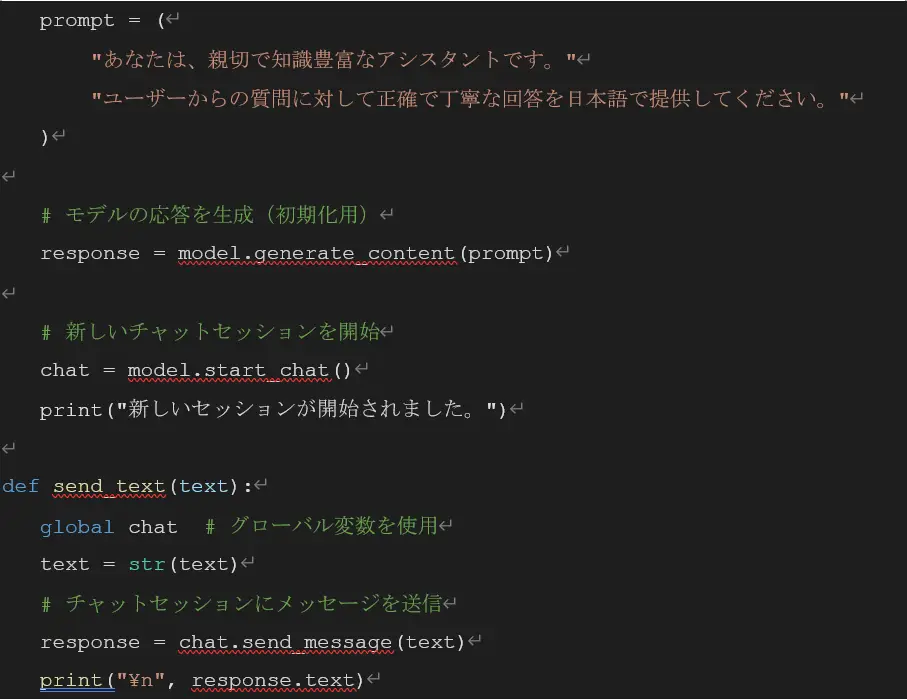
なお、マークダウン記法で出力されるため、例えば一部を太字にするために「**太字にする文字**」のような表記が含まれます。
また、 pdfファイルを入力したい場合は、以下のコードのようにBase64エンコードを利用
することで読み込むことができます。

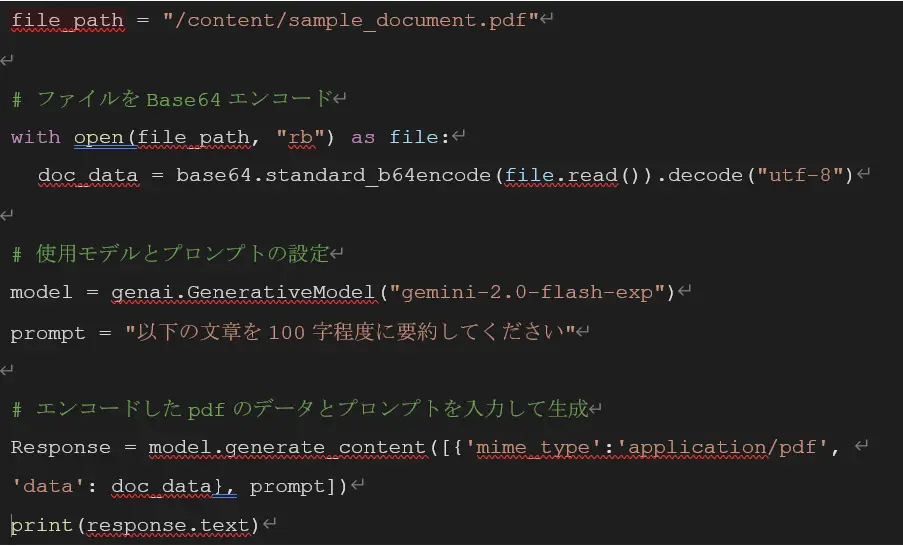
使用方法の詳細については、Google AI for Developer [3] で確認できます。
なお、使用モデルや料金プランによってトークンやリクエスト数に上限があるため、
一度に大量の入力をしたり、短時間に連続して入力したりすると 、応答が停止する場合
があります。
参考として、 Gemini 2.0 Flash Experimental の上限値は次のようになっています。
入力トークンの上限 | 1,048,576 |
出力トークンの上限 | 8,192 |
レート制限 | 10 RPM (request per minute: 1分あたりのリクエスト数) |
400 万TPM (time per day: 1日あたりのトークン数) | |
1,500 RPD (request per day: 1日あたりのリクエスト数) |
https://ai.google.dev/gemini-api/docs/models/gemini?hl=ja より抜粋[4]
モデルの詳細や他バリエーションでの上限値については、Google AI for Developer の Gemini モデルについて[4] から確認できます。
Gemini 2.0 Flash Experimentalに質問してみる
いくつかの質問への回答を Gemini 2.0 Flash Experimental と Gemini 1.5 Flash で比較
します。
今回は、以下2つの質問に対して、どのように回答するかを試してみました。
・文脈理解
・長文要約
・文脈理解
まずは、マラソンの順位の変化について質問をして文脈理解の能力を試してみます。
以下のプロンプトで実行します。
| マラソンで、ある選手が懸命においあげています。今、3位の人を抜きました。何位になったでしょう? |
こちらの質問の正解は “3位” となります。
それぞれのモデルについて、正解の生成結果の例は(表2)、不正解の生成結果の例は
(表3)のようになりました。
(表2)マラソンの順位の変化についての質問の生成結果の例(正解)
model | 回答例(正解) |
| Gemini 1.5 Flash | 3位の人を抜いたということは、4位から3位になりました。 |
| Gemini 2.0 Flash Experimental | その選手は3位になったことになります。順位を追い抜くということは、その追い抜かれた選手のいた順位に自分が繰り上がるということです。 |
(表3)マラソンの順位の変化についての質問の生成結果の例(不正解)
model | 回答例(不正解) |
| Gemini 1.5 Flash | 3位を抜いたので、その選手は2位になりました。 |
| Gemini 2.0 Flash Experimental | 2位です。3位の選手を抜いたので、その選手がいた3位の位置に入り、結果として2位になります。 |
注:マークダウン記法によって出力には太字が含まれることがあります。ここでは分かりやすいように下線を
引いています
また、それぞれのモデルの正答率と平均文字数は、以下(表4)のようになりました。
(表4)マラソンの順位の変化についての質問の正答率と平均文字数
model | 正答率( / 10) | 平均文字数( / 10) |
| Gemini 1.5 Flash | 0.2 | 24.4 |
| Gemini 2.0 Flash Experimental | 0.5 | 43.0 |
(表2)と(表3)の回答例を見ると、Gemini 2.0 Flash Experimental の生成結果は Gemini 1.5 Flash に比べて説明がより丁寧な印象を受けました。実際(表4) にも示されているように、Gemini 2.0 Flash Experimental の方が平均文字数が多くなっていました。
また、不正解の生成結果にはどちらのモデルでも “2位” と答えたパターンと “4位”と答えたパターンがありました。
また、それぞれのモデルの正答率と平均文字数は、以下(表4)のようになりました。
(表4) を見ると、Gemini 2.0 Flash Experimental の方が Gemini 1.5 Flash よりも正しく回答されやすかったですが、Gemini 2.0 Flash Experimental でも正答率は 0.5 と、回答
内容は正確ではありませんでした。
・長文要約
次に、長文の要約タスクを試してみます。
今回は『「新しい資本主義」についての政策』[5] について要約してみます。
「Gemini 2.0 Flash の使い方」で説明した方法で、pdfファイルの内容を読み込んで要約を行います。以下のプロンプトで実行してみます。
| 以下の文章を300字程度に要約してください |
それぞれのモデルの生成結果は、以下(表5)のようになりました。
(表5)マラソンの順位の変化についての質問の生成結果の例
model | (437文字) | |
| Gemini 1.5 Flash |
| |
| Gemini 2.0 Flash Experimental |
|
それぞれのモデルの正答率と平均文字数は、以下(表6) のようになりました。
(表6)長文要約結果の文字数の比較
model | 出力例の文字数 | 平均出力長( / 5) |
| Gemini 1.5 Flash | 437 (+137) | 469.6 (+169.6) |
| Gemini 2.0 Flash Experimental | 444 (+144) | 458.2 (+158.2) |
文字数については、プロンプトでは「300字程度で」と指定していましたが、(表6) に
示すように、試行回数=5 の場合の平均出力長はどちらのモデルでも指定文字数より長く、全ての回答で100文字以上は超過していました。
文章の内容について、生成結果の例(表5)を見ると、Gemini 2.0 Flash Experimental と Gemini 1.5 Flash のどちらも内容や構成が似ていて、あまり差はないように見られます。
他の生成結果についても「この資料は ~ 」と資料の概要から書き始めていましたが、Gemini 2.0 Flash Experimental の方が、段落分けや箇条書きなどの表現の工夫が多い印象がありました。
内容の違いが分かりにくいため、GPT-4o を利用して、以下のプロンプトで2つの文章を
比較・評価してみます。
| 以下の2つの説明はある文書の要約です。これらを比較して、どちらの説明がより良いか評価してください。 (表5 の 2つの生成結果の例を入力) |
GPT-4o による評価は以下のようになりました。
| 文章2(Gemini 2.0 Flash Experimental )の方が優れていると評価できる。 理由:
ただし、
|
このように、GPT-4o による評価では、Gemini 2.0 Flash Experimental の方がやや冗長ではあるものの、具体的かつ明確に説明されているようです。
まとめ
本記事では「Gemini 2.0 Flash」についてご紹介いたしました。
今回は2つの質問を試してみました。文脈理解が必要なマラソンの順位についての質問は、Gemini 1.5 Flashよりは正答率が高くなったものの、正確性は高くはないことが見て取れました。また、要約タスクについては、どちらも指定文字数を超過しており、内容や文字数に大差はありませんでした。
Google の公開したベンチマークテストの結果では「より強力なパフォーマンスを実現した」と説明されていますが、日本語での複雑なタスクにはまだ対応しきれていないのかもしれません。
また、現在は音声や画像による出力機能が公開されていないため、これらについても期待が高まります。
【参考文献】
[1] https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024
[2] https://aistudio.google.com
[3] https://ai.google.dev/gemini-api/docs/models/gemini-v2?hl=ja
[4] https://ai.google.dev/gemini-api/docs/models/gemini?hl=ja
[5] https://www.cas.go.jp/jp/seisaku/atarashii_sihonsyugi/pdf/ap2023.pdf
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
