

人間のフィードバックによる強化学習とデータセット構築

ChatGPTの自然で人間らしい会話能力は、RLHF(Reinforcement Learning from Human Feedback)と呼ばれる技術によって実現されています。
RLHFは、3つの主要なステップから構成されています。
まず、Supervised Fine-Tuning(SFT)では、人間が作成した模範解答を用いて、
モデルに自然な言葉遣いを学習させます。次に、Reward Modeling(RM)では、
人間の好みを反映した報酬モデルを構築し、どの出力が好ましいかを予測できる
ようにします。最後に、Reinforcement Learning(RL)with Proximal Policy
Optimization(PPO)では、報酬モデルからのフィードバックをもとに、強化
学習を用いて、モデルが生成する出力を最適化し、人間にとってより好ましい
回答を生成できるようにします。
これらの3つのステップを通して、ChatGPTは従来の言語モデルを超える高度な
会話能力を獲得しています。
この章では、SFT、RM、RLの3つのステップについて詳細に解説します。
目次
ChatGPTのコア技術:ステップ1 Supervised Fine tuning(SFT)
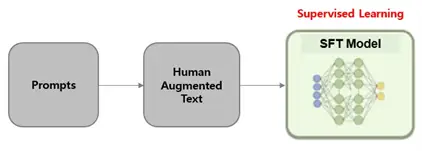
Supervised Fine-tuning[4]
ChatGPTは、どのようにして人間と自然な会話ができるようになったのでしょうか。
前回紹介したRLHF(Reinforcement Learning from Human Feedback)[1][2][3]という
学習方法は、人間のフィードバックを活用して強化学習を行うことで、より人間らしく
自然な会話を実現します。
今回はRLHFについてもっと詳しく説明します。
まず、その学習過程の最初のステップであるSFT(Supervised Fine-tuning)、つまり
教師あり学習によるファインチューニングに焦点を当て、ChatGPT開発の裏側を覗いて
みましょう。
SFTモデルを学習させるためには、まず人間が作成した教師データが必要です。
この教師データは、プロンプト(質問や指示)に対する理想的な回答の組み合わせから
成り立っています。
ChatGPTでは、教師データの収集にあたり、以下の2つのソースを利用しています。
1. 開発チームによる作成:ラベラーや開発者が質の高いプロンプトと回答を手作りします。
2. ユーザーデータの活用:実際のユーザーからの問い合わせデータをサンプリングし、
教師データとして利用します。
このプロセスは非常にコストがかかりますが、その分高品質なデータセットを生成できる
というメリットがあります。
教師データが集まったら、次は事前学習済み言語モデルのファインチューニングです。
ChatGPTでは、GPT-3.5をベースモデルとして採用しています。
限られた量のデータセットでファインチューニングを行う場合、アライメントエラーが発生
する可能性があります。これは、モデルが教師データに過剰適合し、学習データセットに
存在しないプロンプトに対して適切な応答を生成できなくなる現象です。
ChatGPTの開発には、以下の2つの主要な課題があります。
- 課題1:教師データ作成のコスト
質の高い教師データを大量に作成するには、膨大な時間と費用が必要です。
このプロセスは非常にコストがかかります。
※対策※
1. 既存の公開データセットの活用:
公開されている対話データセットを活用することで、コスト削減を目指します。
2. 生成AIによるデータ生成:
人間によるラベル付けではなく、ChatGPT自身を用いて大量のデータを生成すること
を検討します。
- 課題2:事前学習済み言語モデルのコスト
高性能な事前学習済み言語モデル(例:GPT-3.5)の利用には、高額な費用がかかります。このコストは、モデルのトレーニングや運用において大きな負担となります。
※対策※
1. 既存の公開済みモデルの活用:
公開されているモデルを調査し、適用可能なものがあれば積極的に活用します。
2. 独自のモデル作成:
最初の費用はかかりますが、最終的には独自の事前学習済み言語モデルを 作成する
ことも視野に入れます。
SFTデータセットの構築
人間のように自然な会話ができるAIを作るには、膨大な量のデータが必要です。
特に、どんな質問にも正確に答えるAIを作るには「質問と模範解答」のペアを大量に学習
させる必要があります。
これがSFT(Supervised Fine-tuning)データセットと呼ばれるものです。
しかし、質の高いSFTデータセットを作るのは至難の業です。そこで近年注目されているのが、ChatGPTなどの高性能な生成AIを活用したデータセット構築です。
従来のデータセット構築では、人間が手作業で質問と回答を作成していました。しかしこれは非常に時間と労力がかかる作業です。
そこでChatGPTのような高性能な生成AIを使って、ラベル付けやテキストデータの自動生成を行う方法が考えられています。
具体的には、以下のようなプロセスが考えられます。
- ChatGPTに大量のテキストデータを読み込ませ、様々な質問に対する回答を自動生成させる。
- 自動生成された回答を人間がチェックし、修正を加えることで、より自然で正確な回答データを作成する。
SFTデータセットは、一般的にJSONまたはJSONL形式で保存されます。
以下はその一例です。

- "prompt"フィールドには、質問や命令などのテキストデータが保存されます。
- "completion"フィールドには、プロンプトに対する回答が保存されます。
このように、SFTデータセットはAIモデルが自然で正確な回答を生成するための「模範解答集」としての役割を果たします。ChatGPTのような生成AIを活用することで、より効率的に高品質なデータセットを構築し、AIの性能向上に寄与することが期待されます。
ChatGPTのコア技術:ステップ2 Reward Modeling(RM)
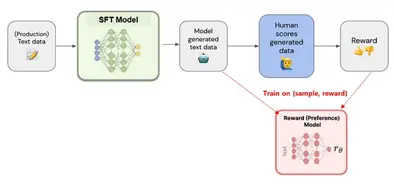
Reward Modeling[4]
ChatGPTがまるで人間のように自然な会話ができるのは、RLHF(Reinforcement Learning with Human Feedback)、つまり人間のフィードバックを学習に取り入れているからです。
今回はRLHFのステップ2である報酬モデル(Reward Model)の学習について解説します。
報酬モデルは、「人間だったら、どの回答を一番良いと思うか」をAIに学習させるための
重要な役割を担います。
その学習手順は以下の通りです。
1. SFTモデルに回答を生成させる:
まずステップ1で学習したSFTモデルに、様々なプロンプト(質問や指示)を与え、
複数の回答を生成させます。
2. 人間が回答をランク付け:
生成された回答を、人間が「好ましさ」の順にランク付けします。
例えば「最も良い」「まあまあ良い」「あまり良くない」のように評価します。
3. ランク付けデータで報酬モデルを学習:
ランク付けされたデータを使って、報酬モデルを学習します。
こうすることで、報酬モデルは人間の好みに合った回答を高く評価できるようになり、
ChatGPTの出力結果をより人間らしいものへと導く「先生」のような役割を果たします。
報酬モデルの学習において、出力結果をランク付けする方法は、以下の2つの点で非常に
効果的です。
- 人間の好みを直接学習:
単に「良い/悪い」の2値で評価するよりも、複数の回答を相対的に評価することで、
より人間の微妙な好みに近い評価基準を学習できます。 - データセットの効率的なスケーリング:
ひとつのプロンプトに対して複数の回答を生成し、ランク付けすることで、限られた
データからより多くの情報を得ることができ、データセットを効率的に拡張できます。
本来、報酬モデルの学習には、人間の評価者によるランク付けが不可欠です。
しかし人件費は高額なため、本研究ではChatGPT自身を活用してランク付けを行うことを
検討しています。
具体的には、プロンプトに対して生成された複数の回答をChatGPTに提示し、それぞれの
回答に対する「好ましさ」を評価させます。
こうすることで、人間の手を借りずに多くのデータを効率的に評価でき、コストを大幅に
削減することが期待されます。
RMデータセットの構築
ChatGPTの学習プロセスにおいて、人間が「良い」と感じる回答をAIに理解させることは
非常に重要です。
そのためには、人間の好みを模倣した報酬モデルを学習させる必要があります。そして報酬
モデルを学習させるためには、報酬モデルデータセットと呼ばれる特殊なデータセットが必要となります。
報酬モデルデータセットは、「プロンプト、複数の回答、そしてそれらの回答に対するランク付け」という情報で構成されています。例えば「富士山について教えてください」というプロンプトに対して、以下のような回答が生成されたとします。
- 回答1:富士山は日本で最も高い山です。
- 回答2:富士山は世界遺産に登録されています。
- 回答3:富士山は四季折々の美しい景色で知られています。
人間がこれらの回答を「好ましさ」の順にランク付けし、その結果をデータセットに記録します。

- "prompt"フィールド:質問や指示
- "completion"フィールド:プロンプトに対する複数の回答
- "ranking"フィールド:回答のランク付け結果(数字が小さいほど好ましい)
報酬モデルデータセットの作成には、通常人間が回答を生成し、ランク付けを行います。
しかし、これは非常に時間とコストがかかる作業です。そこでChatGPTを活用して、回答の
生成とランク付けを自動化することが検討されています。
ChatGPTは、高精度なテキスト生成能力を持つため、人間に近いレベルで自然な回答を生成
することが可能です。
また、複数の回答を比較し、相対的な「好ましさ」を判断することも可能です。ChatGPTの
ような高性能のLLMを活用することで、報酬モデルデータセットの作成を効率化し、より大規模で質の高いデータセットを構築することが期待できます。
ChatGPTのコア技術:ステップ3 Reinforcement Learning(RL)
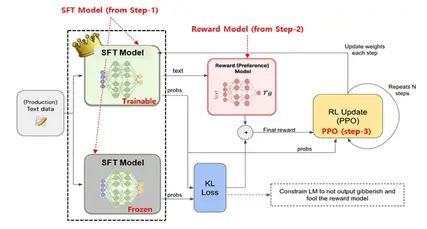
報酬モデル(RM)とPPOの損失計算を用いてSFTモデルをFine-Tuning[4]
ChatGPTの学習過程もいよいよ最終段階に突入します。
ステップ3では、ステップ2で学習した報酬モデルが算出する「報酬」を最大化することで、
SFTモデルをさらに洗練させます。
ステップ3では、強化学習(Reinforcement Learning)という手法を用いてSFTモデルを
ファインチューニングします。
強化学習では、AIは環境との相互作用を通して学習します。行動を起こし、その結果として
報酬を受け取ることで、報酬を最大化するような行動を学習していきます。
ChatGPTの強化学習では、PPO(Proximal Policy Optimization)と呼ばれるアルゴリズム
が用いられます。PPOは、安定して効率的に学習を進めることができる強化学習アルゴリズムとして知られています。
ChatGPTの強化学習パイプラインでは、以下の手順で学習が進められます。
- SFTモデルのコピーを作成:
まず、ステップ1で学習したSFTモデルのコピーを作成します。 - コピーモデルの重みを凍結:
コピーしたモデルの重みを凍結します。これは不適切なテキスト出力を防ぐための
安全対策です。凍結されたモデルは、学習中にパラメータが変更されません。 - KLダイバージェンスの算出:
凍結されたモデルと、学習中の(トレーニング可能な)モデルの出力に対して、
KLダイバージェンスを算出します。KLダイバージェンスは、2つの確率分布の差異を
測る指標です。 - 最終的な報酬の生成:
KLダイバージェンスと報酬モデルが算出した報酬を組み合わせることで、最終的な
報酬を生成します。 - PPOアルゴリズムによるモデルの更新:
PPOアルゴリズムを用いて、最終的な報酬を最大化するように、トレーニング可能な
モデルのパラメータを更新します。
具体的には報酬の損失関数を微分することで、モデルの重みを調整します。
強化学習において、モデルが報酬を最大化しようとすると、予想外の行動をとる可能性があります。
例えば報酬モデルの隙を突いて、意味のないテキストを生成して高い報酬を得ようとするかもしれません。
そこで、ChatGPTでは、SFTモデルのコピーを凍結することで、学習中のモデルが大きく逸脱することを防いでいます。凍結モデルは、いわばAIの「暴走」を防ぐ守護者のような役割を果たしています。ChatGPTの最終調整は、強化学習を用いて報酬を最大化するプロセスです。これにより、AIがより人間らしい、自然な会話を生成できるようになります。
PPOによるRLデータセットの構築
ChatGPTの学習もいよいよ最終段階、ステップ3である強化学習に突入します。
ここでは、PPO(Proximal Policy Optimization)アルゴリズムを用いて、ChatGPTの回答精度をさらに高めていきます。
強化学習を行うためには、特定のデータセットが必要です。
このデータセットは、SFTデータセットからプロンプトデータのみをサンプリングすれば
良いので、比較的簡単に作成できます。回答やランク付けの情報は必要ありません。
以下は、JSON形式のデータセットの例です。

ご覧の通り、必要なのはプロンプトだけです。シンプルですね。
データセットが用意できたら、いよいよ強化学習です。
強化学習では、AIは環境との相互作用を通じて学習します。ChatGPTの場合、「質問(プロンプト)に対する回答」が「行動」にあたり、「報酬モデルが算出した報酬スコア」が「報酬」に当たります。
ChatGPTは、PPOアルゴリズムを用いて、報酬スコアを最大化するように学習を進めます。
つまりより「人間が好ましい」と感じる回答を生成できるよう、試行錯誤を繰り返しながら成長していくのです。
このようにして、ChatGPTは強化学習を通じて、より自然で人間らしい会話ができるようになります。
まとめ
ChatGPTは、人間との自然な会話を実現するために、人間のフィードバックによる強化学習(RLHF、Reinforcement Learning from Human Feedback)を用いて、3段階の学習プロセスを経て開発されました。
まず、人間が作成した質の高い「質問と模範解答」のペアデータを用いた教師ありファインチューニングを行い、次に人間の評価に基づいて報酬モデルを学習、最後に強化学習を通して報酬を最大化することで、より自然で人間らしい会話生成能力を獲得しています。さらにこの章では、各学習段階において、データセットの構築方法を詳細に考察しました。
【参考文献】
[2] L. Ouyang et al., ‘Training language models to follow instructions with human feedback’, arXiv [cs.CL]. 2022.
[3] P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, ‘Deep reinforcement learning from human preferences’, arXiv [stat.ML]. 2023
[4] Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.

記事を書いた人
Jeong Chang-Uk
研究開発部所属エンジニアとして言語系AI開発に従事。早稲田大学大学院国際情報通信研究科博士課程修了。大学院時代にはH.264/AVCやHEVCなどの動画像符号化アルゴリズムを研究。博士号取得後はNLPやAI業界で多数のプロジェクトや研究開発を経験。情報通信分野の工学博士。
関連記事

AI Agent Vol.3【Agent の 学習と評価】

Google のLLM「Gemini 2.0 Flash Thinking」を試してみる

【GroqCloud】 爆速回答!?GroqCloudの実力とは

【まとめ】GPT-4.5 登場!史上最強のAIモデルがリサーチプレビューを公開

AI Agent Vol.2【Agent の 4つの要素】

Google のLLM「Gemini 2.0 Flash」を試してみる

2024年 年末のAI関連発表について

OpenAIが公開したLLMの事実性を評価する指標「SimpleQA」でモデルを測定してみた
AI導入に必須!PoC(概念実証)を成功させる進め方とポイント

The AI Scientist:AIによる論文の自動生成|さまざまな研究テーマを提案させてみる

AI Agent Vol. 1【Single AgentとMulti Agent】

AI活用成功に導く「AI導入アセスメント」とは――数理最適化AI事例をもとにポイントを解説

Llama 3 の日本語継続事前学習モデル「Llama-3-ELYZA-JP-8B」を試してみる

「戻れない変化」を生み出し続ける。コンサルを通して見極める業界DX実現への道筋

サステナビリティ領域で活躍するAI―SDGs×AI活用事例

MetaのオープンLLM「Llama3.2 3B-Instract」の精度を検証してみた|GPT4o-miniとの比較あり

OpenAIの軽量モデル「GPT-4o mini」を試してみる
Microsoft「GraphRAG」とLangchainの知識グラフを活用したRAGを比較

ChatGPTのAPI利用料金比較|最新モデルGPT-4o miniも検証

Langchain+Neo4j で「GraphRAG」を実装してみる

数理最適化ソルバー活用事例|組合せ最適化で社内交流会の班分けを自動化

GoogleのマルチモーダルLLM「Gemini.1.5 Flash」の精度を検証してみる

3次元点群データを用いた物体検出

GPT-4oを活用した画像検索システムの構築方法

Pythonコーディングを簡単に|LangChainで効率化【LLMことはじめ Vol.2】

Copilot for Microsoft 365で「PowerPoint」を使いこなす

Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり

3次元点群データとAIを用いたオガ粉の体積計測

Llama 3 の日本語継続事前学習モデル「Llama 3 Youko 8B」を試してみる|他LLMとの比較あり

RAG(Retrieval Augmented Generation)を「Command R+」で試してみた|精度をGPT-4 Turboと比較

Wood Powder Volume Calculation using Point Cloud Data and AI

Dify(ディファイ)をGoogle Cloudにデプロイしてみた

“Azure OpenAI”で始めるPythonプログラミング【LLMことはじめ Vol.1】

Combating the Malicious Use of AI-Powered Image Editing: A Deep Technical Dive

最新版「GPT-4 Turbo」を試してみた|GPT-4oとの比較あり(5/14追記)

PrecisionとRecallを何度も調べ直さないために

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AIというツールを使い 「生命たらしめるもの」が何かを見つけたい【調和技研✖️AIの旗手 Vol.4】

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

AIアルゴリズムの構築には、 課題の本質を見極めることが重要 【調和技研✖️AIの旗手 Vol.3】

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

Stable Diffusionを使って異常画像データを生成できるか検証してみた

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
